数据库管理 日志优化 数据库log问题解决方法及常见log难题应对策略

📊 数据库日志那些事儿:从抓狂到优雅的优化指南
场景还原:凌晨3点,报警短信炸醒你——数据库磁盘爆满!登录服务器一看,/var/log/mysql目录下堆积了200GB的日志文件,而业务系统已经卡成PPT...😱 这种"日志灾难"你是否似曾相识?
🔍 一、数据库日志的"生存法则"
1 日志家族的秘密成员
- 错误日志(Error Log):记录启动/运行时的致命错误(比如
Can't create table 'xxx' (errno: 28)) - 二进制日志(Binlog):主从复制的生命线,但可能吃掉一半磁盘(某电商曾因未设置
expire_logs_days导致500GB冗余日志📉) - 慢查询日志(Slow Query Log):性能优化的金矿,但全量开启会让磁盘IO飙升
- 事务日志(Redo/Undo Log):InnoDB的"后悔药",WAL机制的核心
2 2025年新趋势
- AI日志分析:像ChatDBA这样的工具能自动标记异常模式(比如突然暴增的
Deadlock found) - 云原生日志:K8s环境下日志自动轮转成为标配(但要注意PVC存储配额!)
⚡ 二、五大经典翻车现场 & 急救方案
🚨 Case 1: "磁盘已满"连环追杀
症状:No space left on device报警,连vim都无法运行
根因:未限制Binlog数量或慢查询日志持续写入
急救三步法:
lsof -n | grep deleted找到被进程占用的已删除大文件- 临时扩容:
mysql -e "PURGE BINARY LOGS BEFORE NOW() - INTERVAL 1 DAY" - 长期方案:设置
expire_logs_days=7+ 日志分级存储
🚨 Case 2: 慢查询日志拖垮性能
典型场景:某APP上线新功能后,日志磁盘IOPS冲到100%
优化组合拳:

-- 只记录超过2秒的查询 SET GLOBAL long_query_time = 2; -- 禁用全表扫描记录 SET GLOBAL log_queries_not_using_indexes = OFF; -- 用Percona的pt-query-digest分析日志
🚨 Case 3: 主从复制因日志中断
经典错误:Master has purged binary logs containing missing transactions
预防措施:
- 从库设置
relay_log_space_limit = 10G - 监控主从延迟:
SHOW SLAVE STATUS中的Seconds_Behind_Master
🛠️ 三、高手都在用的日志管理技巧
1 智能日志轮转策略
# MySQL配置文件示例 [mysqld] log_error = /var/log/mysql/error.log log_error_verbosity = 3 # 2025年新增参数,控制错误详细等级 slow_query_log = 1 slow_query_log_file = /mnt/ssd_logs/mysql-slow.log # SSD存放高频日志
2 日志分析"作弊码"
- Binlog解剖术:
mysqlbinlog --start-datetime="2025-07-01 09:00:00" \ --base64-output=DECODE-ROWS -v mysql-bin.000123
- 错误日志关键词监控:
# 监控每小时OOM错误次数 SELECT COUNT(*) FROM error_log WHERE message LIKE '%Out of memory%' AND event_time >= NOW() - INTERVAL 1 HOUR;
🌈 四、未来已来的日志黑科技
1 预测性日志压缩
通过机器学习预测日志价值,自动对低频日志采用Zstandard压缩(某金融系统实测节省70%空间🎉)

2 区块链日志存证
对审计日志进行Merkle Tree哈希处理,防止DBA私自篡改(合规性要求高的场景必备)
📝 终极 checklist
✅ 每日检查df -h和日志目录大小
✅ 为不同日志类型配置独立的存储策略
✅ 重要操作前手动触发FLUSH LOGS
✅ 使用log_rotate工具而非简单rm

💡 好的DBA不是不会出问题,而是让问题在爆发前就被日志暴露!下次当你面对海量日志时,希望这些方法能让你从容微笑~ ✨
本文由 松采南 于2025-07-25发表在【云服务器提供商】,文中图片由(松采南)上传,本平台仅提供信息存储服务;作者观点、意见不代表本站立场,如有侵权,请联系我们删除;若有图片侵权,请您准备原始证明材料和公证书后联系我方删除!
本文链接:https://vps.7tqx.com/wenda/443732.html
最新文章
-

必读|国际服VPS加速全攻略 实用技巧与安全预警【游戏速通指南】
2025-08-03 -

Redis 微服务 使用Redis开发微服务的轻量化方案,基于redis实现高效微服务架构
2025-08-03 -

高性能服务器🚀超大内存体验 5T内存是什么感觉?带你深入了解Spinservers美国服务器
2025-08-03 -
角色攻略⚡实用干货⚡梦见月瑞希必备圣遗物搭配与实战技巧全解析
2025-08-03 -
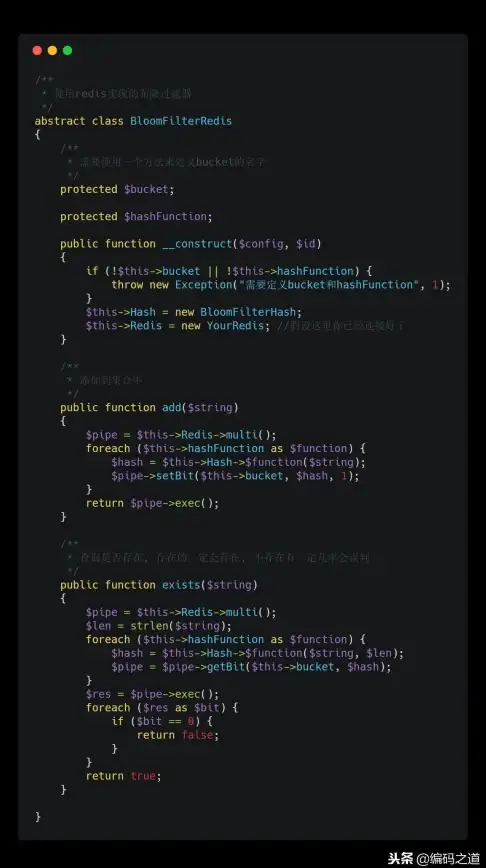
Redis优化 应用提升 Redis突破助力应用技术升级,redis多种应用技术解析
2025-08-03 -

【云计算热讯】流量高效分配技巧!速查|云服务器加速配置精要—实用配置指南
2025-08-03 -
边缘计算|类型分析 浅析中心词在边缘计算的四种类型
2025-08-03 -

探究|爆款推荐|云计算快讯】北京移动VPS硬核性价比实测解读—省钱购入秘籍
2025-08-03

发表评论