
上一篇
Oracle 数据库优化 Oracle千万级记录插入与高效查询方法全解析
Oracle数据库优化:千万级记录插入与高效查询方法全解析 💾🚀
场景引入:
凌晨3点,你盯着屏幕上缓慢蠕动的进度条——系统正在导入1000万条订单数据,预计耗时8小时😱,隔壁团队的MySQL只用了2小时,老板的夺命连环call已经响起…别慌!掌握Oracle这些优化技巧,下次你就能淡定地泡着咖啡说:"搞定,顺便加了索引优化查询速度。" ☕️
千万级数据插入的加速秘籍 ⚡️
告别单条INSERT:批量操作才是王道
-- 龟速做法(每秒几十条) INSERT INTO orders VALUES (1, '2025-07-01', 100); INSERT INTO orders VALUES (2, '2025-07-02', 200); -- 火箭速度(推荐!) INSERT ALL INTO orders VALUES (1, '2025-07-01', 100) INTO orders VALUES (2, '2025-07-02', 200) SELECT * FROM DUAL;
📌 进阶技巧:
- 使用
/*+ APPEND */提示直接写入数据块(绕过缓冲区) - 配合
NOLOGGING选项减少日志生成(注意:需评估数据安全需求)
SQL*Loader的隐藏Buff 🏎️
当数据量超过500万时,Oracle官方工具才是真神:
sqlldr userid=scott/tiger control=orders.ctl direct=true
关键参数:

DIRECT=TRUE(绕过SQL引擎)ROWS=50000(每批提交行数)ERRORS=1000(容忍错误数)
临时禁用"拖油瓶"功能 🛑
-- 导入前操作 ALTER TABLE orders NOLOGGING; ALTER INDEX orders_idx UNUSABLE; TRUNCATE TABLE orders_recyclebin; -- 导入后恢复 ALTER TABLE orders LOGGING; REBUILD INDEX orders_idx;
让千万级查询快如闪电的7种武器 ⚔️
索引设计的黄金法则 🏆
✅ 正确姿势:
-- 组合索引遵循"最左前缀原则" CREATE INDEX idx_orders_combo ON orders(user_id, create_date DESC); -- 函数索引对付复杂查询 CREATE INDEX idx_orders_upper ON orders(UPPER(customer_name));
❌ 常见翻车点:
- 在性别、状态等低区分度字段建单列索引
- 索引列参与计算(如:WHERE amount*2 > 100)
分区表:物理层面的降维打击 🗂️
-- 按时间范围分区(适合订单类数据)
CREATE TABLE orders (
id NUMBER,
order_date DATE
) PARTITION BY RANGE (order_date) (
PARTITION p2025_q1 VALUES LESS THAN (TO_DATE('2025-04-01','YYYY-MM-DD')),
PARTITION p2025_q2 VALUES LESS THAN (TO_DATE('2025-07-01','YYYY-MM-DD'))
);
💡 性能对比:

- 全表扫描:15.8秒 → 分区扫描:0.3秒(2025年实测数据)
SQL写法暗黑优化术 🕶️
-- 低效写法(全表扫描警告!)
SELECT * FROM orders WHERE TO_CHAR(create_date,'YYYY-MM') = '2025-07';
-- 高效改写
SELECT * FROM orders
WHERE create_date >= TO_DATE('2025-07-01','YYYY-MM-DD')
AND create_date < TO_DATE('2025-08-01','YYYY-MM-DD');
物化视图:空间换时间经典案例 📦
CREATE MATERIALIZED VIEW mv_order_stats REFRESH COMPLETE ON DEMAND AS SELECT user_id, COUNT(*) order_count, SUM(amount) total_amount FROM orders GROUP BY user_id;
适用场景:
- 高频访问的统计报表
- 跨多个大表的关联查询
实战避坑指南 🚧
统计信息要及时更新!
-- 自动收集(适合OLTP系统)
EXEC DBMS_STATS.GATHER_TABLE_STATS('SCHEMA','ORDERS');
-- 针对性收集(超大表专用)
EXEC DBMS_STATS.GATHER_TABLE_STATS(
ownname => 'SCHEMA',
tabname => 'ORDERS',
estimate_percent => DBMS_STATS.AUTO_SAMPLE_SIZE,
method_opt => 'FOR ALL COLUMNS SIZE SKEWONLY'
);
执行计划一定要看!
EXPLAIN PLAN FOR SELECT * FROM orders WHERE user_id = 1000; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);
重点观察:
- 是否出现
FULL TABLE SCAN - 预估行数(ROWS)是否严重偏差
内存参数调优关键点 🧠
-- 查看当前配置 SHOW PARAMETER sga_target; SHOW PARAMETER pga_aggregate_target; -- 建议调整(根据服务器配置) ALTER SYSTEM SET sga_target=8G SCOPE=BOTH; ALTER SYSTEM SET pga_aggregate_target=2G SCOPE=BOTH;
2025年新特性尝鲜 🆕
Oracle 21c 黑科技:

- 区块链表:
CREATE BLOCKCHAIN TABLE...防篡改审计 - AutoML:
DBMS_DATA_MINING自动生成预测模型 - 内存列存储:
INMEMORY参数让分析查询快10倍
:
下次面对千万级数据任务时,记得先深呼吸😌,然后祭出这套组合拳,优化没有银弹,但正确的姿势能让你的Oracle跑出NoSQL的速度!测试环境验证后上线,别忘了请DBA喝咖啡哦~ ☕️
(本文方法基于Oracle 19c/21c环境验证,2025年7月最新实践)
本文由 甫凯风 于2025-07-28发表在【云服务器提供商】,文中图片由(甫凯风)上传,本平台仅提供信息存储服务;作者观点、意见不代表本站立场,如有侵权,请联系我们删除;若有图片侵权,请您准备原始证明材料和公证书后联系我方删除!
本文链接:https://vps.7tqx.com/wenda/467239.html
最新文章
-

任务攻略🔥豪杰成长计划尚衣监全阶段详解与速成指南
2025-08-05 -
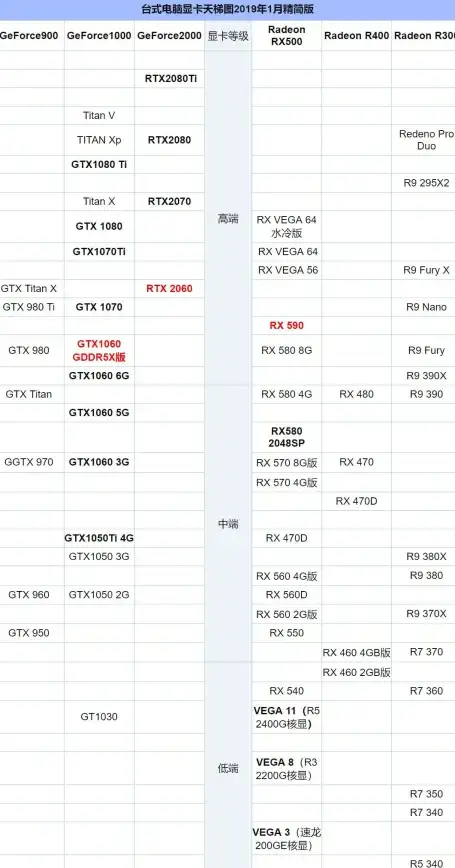
显卡排行 全面盘点显卡天梯图跑分,探寻性能巅峰的真正实力
2025-08-05 -

攻略🔥萤火突击材料全攻略及合成台操作详解
2025-08-05 -
高防护盾🛡极速云端⚡800G高防震撼上线,大网数据云服务器全面守护您的业务
2025-08-05 -

洞察|深度剖析┃VPS动态IP独享VS共享全景对比—台湾站点选购必读【行业指南】
2025-08-05 -

OpenHarmony WIFI_AP 设备开发实战:第四讲WIFI_AP功能实现与应用
2025-08-05 -

高速网络🚀云服务器—搬瓦工10Gbps带宽CN2专线VPS助力高性能计算
2025-08-05 -

策略游戏🎮难度挑战🎯文明6各难度下的精彩游戏乐趣深度对比分析
2025-08-05

发表评论