Oracle报错 会话序列溢出 ORA-08000:maximum number of session sequence lists exceeded 故障修复与远程处理

Oracle报错:会话序列溢出(ORA-08000)故障修复指南
场景引入:
凌晨3点,你正睡得香甜,突然被一阵急促的手机铃声惊醒——生产数据库告警了!日志里赫然出现"ORA-08000: maximum number of session sequence lists exceeded"的报错,应用团队反馈批量任务全部卡死,作为DBA,你揉了揉眼睛,知道今晚又得和Oracle"斗智斗勇"了...
错误本质解析
这个看起来晦涩的报错,其实直指Oracle的一个隐藏瓶颈:
ORA-08000 表示Oracle实例中会话级序列缓存(session sequence cache)的链表数量超过了内部限制,就是太多会话同时在频繁调用序列(SEQUENCE),把Oracle的"序列号码簿"给挤爆了。
典型触发场景:

- 高并发应用批量插入数据(比如电商秒杀生成订单号)
- 中间件连接池配置过大(如WebLogic默认连接数+序列缓存双重放大)
- 序列设置
CACHE值过高但NOORDER(常见于RAC环境)
紧急止血方案
方案1:动态调整参数(无需重启)
-- 查看当前设置(单位是链表个数,默认约等于进程数的2倍) SELECT name, value FROM v$parameter WHERE name LIKE '%sequence%'; -- 临时调高限制(根据服务器内存调整,一般不超过10000) ALTER SYSTEM SET "_sequence_cache_lists"=2000 SCOPE=BOTH;
💡 注意:这是下划线参数(隐藏参数),Oracle不保证向前兼容
方案2:优化序列使用模式
-- 检查被频繁调用的序列(重点关注CACHE值) SELECT sequence_owner, sequence_name, cache_size FROM dba_sequences WHERE cache_size > 100; -- 修改热点序列配置(降低缓存或启用排序) ALTER SEQUENCE app_order_seq CACHE 20 ORDER; -- RAC环境必须加ORDER
方案3:应用层改造
如果无法立即修改数据库,可要求开发人员:
- 批量操作改用
SELECT seq.nextval FROM dual一次性获取多个值 - 在连接池配置中减少
initialSize和maxActive值
根治性解决方案
| 优化方向 | 具体措施 |
|---|---|
| 序列设计 | 非关键业务序列改用NOCACHE,高并发序列采用CACHE + ORDER组合 |
| 架构层面 | 引入分布式ID生成器(如雪花算法)分担数据库压力 |
| 监控预警 | 部署脚本监控v$session_wait中enq: SQ - contention等待事件 |
| 参数调优 | 在内存充足的服务器上设置_sequence_cache_hash_buckets为质数(如1021) |
远程处理要点
当需要通过VPN处理客户现场问题时:
-
快速诊断三板斧:
-- 检查当前序列等待 SELECT event, count(*) FROM v$session_wait GROUP BY event; -- 查看序列缓存命中率 SELECT name, gets, misses, 1-(misses/gets) "HitRatio" FROM v$sequence_cache WHERE gets > 0;
-
谨慎操作原则:

- 优先在测试环境验证
_sequence_cache_lists调整效果 - 修改生产序列属性前确保应用有重试机制
- 优先在测试环境验证
-
事后必须:
- 保留
AWR报告中的"Segment Statistics"部分 - 记录最终解决方案到CMDB(配置管理数据库)
- 保留
知识延伸
为什么Oracle要有这个限制?其实这是Oracle在内存管理和锁竞争之间的权衡:
- 每个会话缓存序列值需要维护独立的内存结构
- 链表数量过多会导致
latch free等待(可通过v$latch_misses验证) - 在Oracle 23c中,该限制已默认提升至32768
最后提醒:遇到ORA-08000时切勿盲目增加_sequence_cache_lists,就像通过调高冰箱温度来解决食物腐烂问题——真正的症结往往在于应用架构是否需要引入分布式ID生成策略。
(本文技术要点基于Oracle 19c企业版验证,部分参数在12c及之前版本可能不存在)
本文由 甫凯风 于2025-07-30发表在【云服务器提供商】,文中图片由(甫凯风)上传,本平台仅提供信息存储服务;作者观点、意见不代表本站立场,如有侵权,请联系我们删除;若有图片侵权,请您准备原始证明材料和公证书后联系我方删除!
本文链接:https://vps.7tqx.com/wenda/488747.html
最新文章
-

游戏攻略🔥爆梗找茬王阴阳怪气全关卡深度解析详细指南
2025-08-02 -
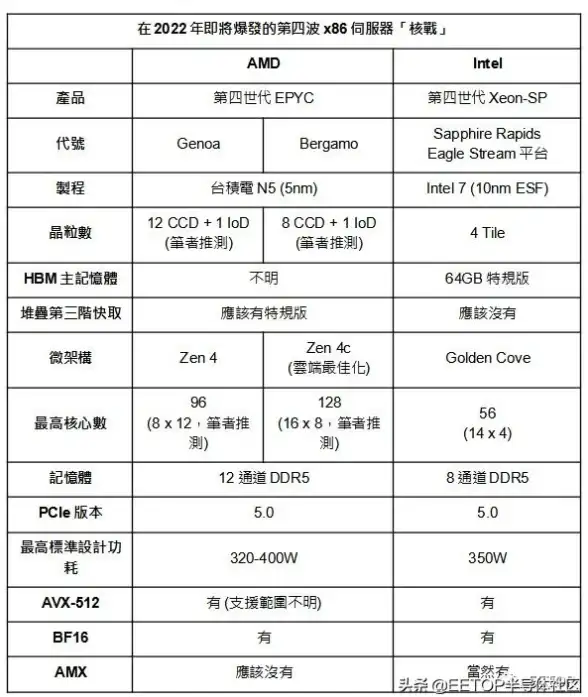
云服务器🚀高性能|AMD EPYC赋能ISIF Cloud香港10Gbps优化带宽全新上线
2025-08-02 -
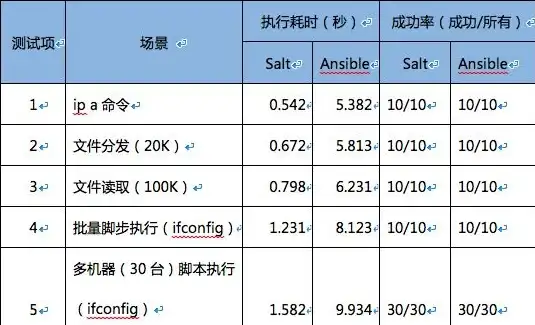
全新智能升级|高效掌控服务器在线人数|IT运维优化方案】爆款实用,技术人员必看
2025-08-02 -

科技新品🌟折叠屏|华为2023款折叠屏新机震撼发布,售价信息备受关注
2025-08-02 -
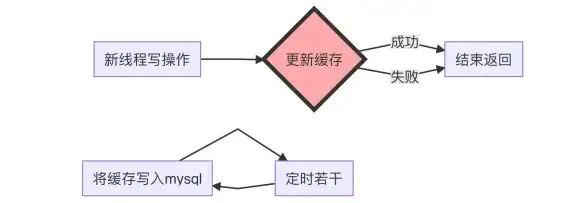
数据库备份 数据安全 mysql整库备份全攻略,全面解析MySQL整库高效备份方法
2025-08-02 -

重磅⚡攻略⚡植物大战僵尸2挂件重置全技巧+超快速恢复秘籍!
2025-08-02 -

策略秘籍 PVP技巧 御魂搭配 阴阳师》孔雀明王PVP御魂养成全攻略,实战发挥全面提升!
2025-08-02 -
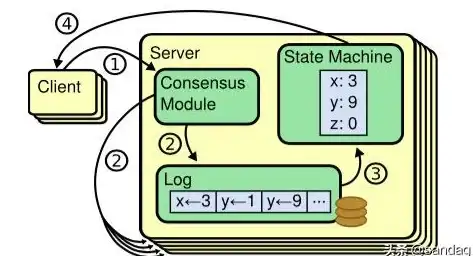
分布式一致性|存储架构 Raft与Paxos在分布式存储系统中的应用区别分析
2025-08-02

发表评论