
上一篇
Redis运维|服务器监控 通过Redis命令获取服务器信息,快速查看redis info参数
Redis运维实战:快速掌握服务器监控技巧
最新动态:截至2025年7月,Redis 7.2版本进一步优化了INFO命令的输出结构,新增了对NVMe存储设备的性能监控指标,运维人员现在可以更精准地获取SSD寿命和吞吐量数据。
为什么需要监控Redis服务器?
Redis作为内存数据库,性能瓶颈往往出现在内存、CPU或网络层面,一个突发的内存溢出或连接数激增就可能让服务瘫痪,通过Redis内置命令获取实时数据,比依赖第三方工具更直接高效,尤其在紧急排障时能快速定位问题。
核心命令:INFO的全方位解读
执行redis-cli info会返回几十项参数,别慌!我们只需关注关键指标:

内存监控(info memory)
# 示例输出关键字段 used_memory: 3.2GB # 实际占用内存 maxmemory: 8GB # 配置的最大内存 mem_fragmentation_ratio: 1.5 # >1.5表示碎片严重
运维口诀:
- 若
used_memory接近maxmemory,立刻扩容或清理缓存 - 碎片率超过1.5时,用
memory purge(Redis 6.2+)或重启实例
性能指标(info stats)
instantaneous_ops_per_sec: 12000 # 每秒操作数 total_connections_received: 150万 # 历史总连接数 rejected_connections: 50 # 超过maxclients的被拒连接
典型问题:
- 突增的
rejected_connections:检查maxclients设置和客户端连接泄漏 - ops持续>5万:考虑分片或升级CPU
持久化监控(info persistence)
rdb_last_bgsave_status:ok aof_last_write_status:err # 最后一次AOF写入状态
红色警报:
任何持久化错误都可能导致数据丢失,需立即检查磁盘空间和IO性能
高阶技巧:快速提取关键参数
按需过滤信息
# 只查看内存和客户端信息 redis-cli info memory clients
实时监控延迟
redis-cli --latency -i 5 # 每5秒采样一次延迟
危险指标自动预警(Shell脚本片段)
#!/bin/bash CRITICAL=$(redis-cli info memory | grep -E "mem_fragmentation_ratio|used_memory_human") if [[ $CRITICAL =~ "ratio:2.0" || $CRITICAL =~ "GB" ]]; then echo "警告!内存异常: $CRITICAL" | mail -s "Redis告警" admin@example.com fi
常见误区与解决方案
❌ 误区1:只监控used_memory
✅ 正确做法:同时关注lazyfree_pending_objects(延迟释放对象数),避免异步删除堆积

❌ 误区2:忽略connected_slaves
✅ 正确做法:主从架构下,定期检查从库数量,防止脑裂
2025年新特性:NVMe监控参数
Redis 7.2+版本新增:
# 执行info storage获取SSD健康度 storage_nvme_life_remaining: 85% # 剩余寿命 storage_throughput: 1.2GB/s # 磁盘吞吐
本文由 冠觅 于2025-07-31发表在【云服务器提供商】,文中图片由(冠觅)上传,本平台仅提供信息存储服务;作者观点、意见不代表本站立场,如有侵权,请联系我们删除;若有图片侵权,请您准备原始证明材料和公证书后联系我方删除!
本文链接:https://vps.7tqx.com/wenda/496302.html
最新文章
-

游戏攻略🔥弹弹堂四象魔石获取难度全揭秘排行榜
2025-08-05 -

RocketMQ 生产者用法 我怎么不知道RocketMQ生产者原来有这么多不同的使用方式?
2025-08-05 -
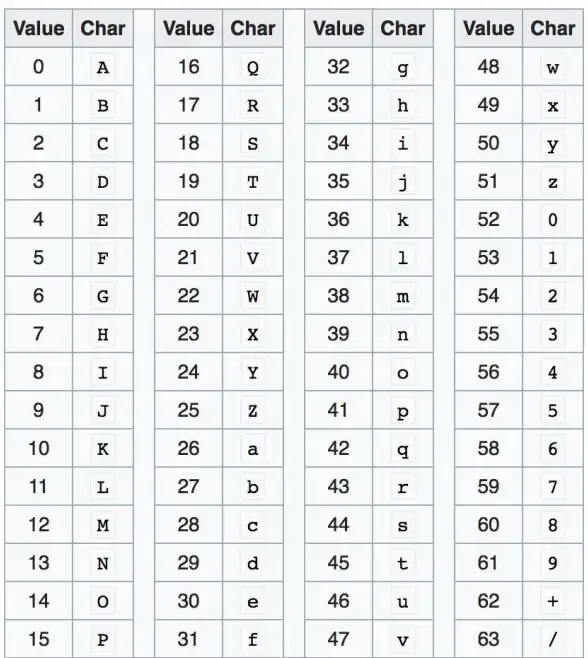
邮件管理📧电脑和手机上如何查看和读取.eml文件
2025-08-05 -

BT下载提醒|北美VPS性能优化秘籍—实用指南】亮点解析!
2025-08-05 -
重装系统🚀32位win7系统一键重装详细步骤解析
2025-08-05 -

数据中心,大带宽-湖南湘潭数据中心,冬邦云电信大带宽服务保障
2025-08-05 -

🔥装备爆料🔥实力解析🔥洞悉《地下城与勇士:起源》60级史诗手炮爆弹双陨星技能实战表现!
2025-08-05 -
显卡排行🔥2022年笔记本显卡天梯图全解析:权威对比30款新品,轻松选购最佳笔记本
2025-08-05

发表评论