
上一篇
实用技巧速览 高效数据采集指南 最新火车头采集器抓取实用攻略【精选推荐】
本文目录:
- 🔥 开篇暴击:为什么合规抓取比命还重要?
- 🔧 第一步:环境搭建(保姆级教程)
- 💡 第二步:精准定位采集目标
- 👇 第三步:设置黄金采集规则
- ⚠️ 第四步:合规避坑指南(血泪总结)
- 🧹 第五步:数据清洗黑科技
- 🎉 终极彩蛋:合规检测清单
- 📌 新手常见QA
🚂【数据采集新纪元】2025年火车头采集器V10.28神操作全解析!💻
家人们!刚从官方扒到重磅消息——火车头采集器5月更新的V10.28版本直接封神!新增的DeepSeek AI数据处理功能让数据提取效率起飞,还能精准抓取任意层级JSON数据,合规抓取再也不怕翻车!🎉
🔥 开篇暴击:为什么合规抓取比命还重要?
最近总有人哭诉:"账号秒封""数据用不了"😭!宝子们!现在网站反爬机制比间谍片还刺激,不懂合规流程分分钟踩雷!今天手把手教你用火车头采集器,既能高效抓取,又能避开法律风险,新手也能秒变老司机!🚀
🔧 第一步:环境搭建(保姆级教程)
1️⃣ 下载安装包:认准火车采集器官网(2025年7月最新版V10.28),别去野鸡网站!
2️⃣ 配置要求:必须装.NET4.6框架,电脑卡顿的宝子记得关掉其他吃内存的软件~
3️⃣ 基础设置:
- 打开软件先点「系统设置」🔧
- 设置「默认编码」为UTF-8(防乱码神器)
- 勾选「自动处理Cookie」(模拟真人操作关键!)
💡 第二步:精准定位采集目标
案例实操:假设我们要抓取某电商平台的商品信息
1️⃣ 新建站点:右键「站点管理」→「新建站点」,站点名写「XX电商」🏪,网址深度选「1」(自动抓列表页+详情页)。
2️⃣ 新建任务:右键站点→「从该站点新建任务」,任务名写「手机专区」📱,起始网址填真实地址。

👇 第三步:设置黄金采集规则
重点来了!这一步决定你能抓到什么数据!
1️⃣ 采集网址规则:点击「采集网址」标签页,用「自动识别」抓取列表页链接🔗,遇到分页?用通配符「https://example.com/list_*.html」搞定!
2️⃣ 内容提取规则:
- 」「价格」「图片」等字段📋
- 独家技巧:用正则表达式过滤无关内容!
<div class="price">(.*?)</div>
- 图片下载记得勾选「保存到本地」🖼️
3️⃣ 发布设置:导出格式选「Excel」或「JSON」📊,路径用变量自动命名文件,}_{时间}.xlsx
⚠️ 第四步:合规避坑指南(血泪总结)
1️⃣ 频率控制:千万别用默认的1秒/次!建议设为3-5秒/次⏳,勾选「随机延迟」(模拟真人浏览)
2️⃣ User-Agent伪装:在「HTTP请求头」里填上真实浏览器信息🌐,推荐用Chrome的UA:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36... 3️⃣ IP代理轮换:企业级用户必看!在「系统设置」→「代理服务器」里配置🔄,免费代理?慎用!容易集体失效!
🧹 第五步:数据清洗黑科技
抓完数据别急着用!V10.28的「DeepSeek」功能绝了!
1️⃣ 自动去重:勾选「去除重复行」🗑️
2️⃣ 智能清洗:用「正则替换」删掉HTML标签🧹,比如把<br/>替换成换行符。
3️⃣ 数据转换:价格字段批量乘以0.9(打九折)💸,日期格式统一成YYYY-MM-DD。
🎉 终极彩蛋:合规检测清单
采集前必做这5件事!
1️⃣ 查看目标网站的robots.txt文件⚠️
2️⃣ 联系网站管理员获取授权(商业项目必做!)📧
3️⃣ 限制采集时间为9:00-18:00(避开服务器高峰)⏰
4️⃣ 采集量≤网站日均PV的10%(安全阈值)📉
5️⃣ 定期更新采集规则(网站改版后必改!)🔄

📌 新手常见QA
Q:为什么采集到乱码?
A:检查编码设置是否为UTF-8,或手动指定GBK🔠
Q:遇到验证码怎么办?
A:用OCR工具识别,或手动输入后保存Cookie🍪
Q:如何避免被封IP?
A:搭配代理IP池,频率设置成「5-10秒随机延迟」🎭
🚀 学会这些神操作,你就是数据采集界的六边形战士!记得点赞收藏,下次更新教你怎么用火车头抓取动态渲染的JavaScript页面!💥
本文由 云厂商 于2025-08-01发表在【云服务器提供商】,文中图片由(云厂商)上传,本平台仅提供信息存储服务;作者观点、意见不代表本站立场,如有侵权,请联系我们删除;若有图片侵权,请您准备原始证明材料和公证书后联系我方删除!
本文链接:https://vps.7tqx.com/fwqgy/500824.html
最新文章
-

Redis应用 办公效率提升 使用Redis,大大提高办公效率,使用redis好处
2025-08-06 -
新手建站 实战技巧全收录 宝塔面板本地部署与FTP全程指南【网站运维】
2025-08-06 -

时尚🔥颜值🔥传说,DNF至尊装扮最强排行榜推荐
2025-08-06 -

角色解析•玩法攻略•属性揭秘|揭秘《封神幻想世界》73宝宝属性优劣及最强选择攻略!
2025-08-06 -
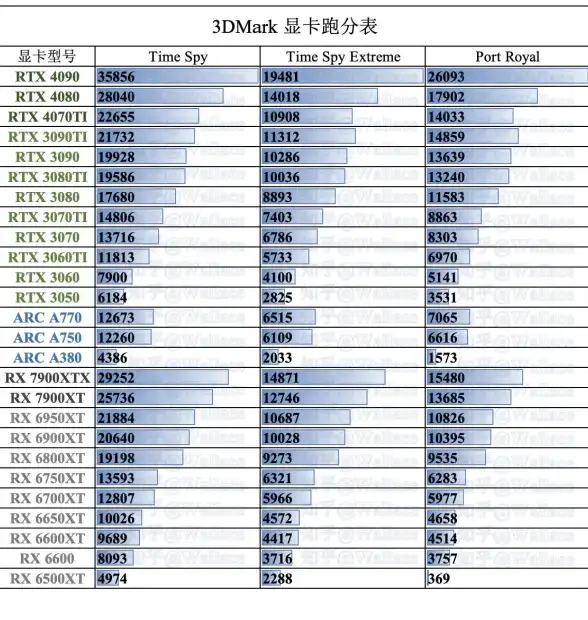
显卡推荐🔥11月显卡桌面天梯图全新发布,权威排名助你精准挑选理想显卡
2025-08-06 -

CDN发展,节点升级 CDN行业海南儋州节点能级提升之路探索
2025-08-06 -
Oracle报错 网络服务器故障 ORA-06107:NETTCP网络服务未找到 远程处理与修复方法
2025-08-06 -
重磅提醒|赶在系统降级前—Win7用户必备安全备份指南与风险预警🔒系统防护聚焦】
2025-08-06

发表评论