
上一篇
多层缓存 高效实战 技术攻关】缓存服务器最优利用与体系搭建策略
🚀多层缓存·高效实战:让服务器性能飞起来的“降龙十八掌”
🎬场景引入:当双十一大促撞上缓存“雪崩”
想象一下:你是一家电商公司的CTO,双十一零点的钟声即将敲响,服务器却突然卡成PPT——用户疯狂点击“立即购买”,页面却像老牛拉车般转圈圈,订单量断崖式下跌。
这可不是科幻片!去年某头部电商就因缓存雪崩导致30分钟内GMV暴跌40%,CTO连夜被董事会“喝茶”。
但别慌! 今天带你拆解2025年最硬核的多层缓存实战攻略,用“三级火箭”架构+Redis神操作,让你的系统扛住每秒百万级并发!
🔥第一层:本地缓存——给CPU装上“氮气加速”
💡为什么需要本地缓存?
当用户反复查询“iPhone 17库存”,数据却要穿越千山万水到数据库“旅游”一圈,这延迟能不感人吗?
本地缓存就是CPU的“贴身保镖”,把热数据存在内存里,访问速度直逼光速(0.1微秒级)!

🛠️实战代码:Caffeine+双缓存策略
// L1缓存:Caffeine(纳秒级响应,容量1万)
LoadingCache<String, Product> l1Cache = Caffeine.newBuilder()
.maximumSize(10_000)
.expireAfterWrite(1, TimeUnit.MINUTES)
.build(key -> db.queryProduct(key));
// 双缓存防穿透:当L1未命中,查L2前先塞个“空值占位符”
if ((product = l1Cache.get(key)) == null) {
l1Cache.put(key, EMPTY_STUB); // 防止缓存穿透攻击
product = l2RedisCache.get(key);
}
⚠️避坑指南:
- 慎用
@Cacheable注解,手动控制缓存更新更安全 - 大Key拆分:超过10KB的数据直接Pass,改用Redis集群
🚀第二层:Redis集群——分布式缓存的“瑞士军刀”
📊2025年Redis最新数据:
- 某零售巨头用Redis将库存查询延迟从800ms砍到47ms
- 金融行业平均缓存命中率飙升至89%(2024年仅62%)
🔧Redis实战三板斧:
智能缓存预热
# 凌晨3点自动执行(K8s CronJob) 0 3 * * * curl http://api.example.com/preheat?key=hot_products
# Python预热脚本(自动抓取Top 1000热销商品)
def preheat_redis():
hot_skus = db.query("SELECT sku FROM sales_rank WHERE rank <= 1000")
pipe = redis.pipeline(transaction=False)
for sku in hot_skus:
pipe.set(f"sku:{sku}", json.dumps(get_product_detail(sku)), ex=86400)
pipe.execute()
缓存雪崩“三重保险”
- 随机过期时间:
redis.expire(key, 3600 + random(600)) - 永不过期+后台更新:启动独立线程每5分钟刷新数据
- 熔断降级:用Hystrix监控QPS,超阈值直接返回默认值
分布式锁“防身术”
// RedLock算法防脑裂(需部署5个Redis节点)
String lockKey = "order_lock_" + orderId;
String token = UUID.randomUUID().toString();
try {
Boolean locked = redis.set(lockKey, token, "NX", "PX", 30000);
if (locked) {
// 处理订单逻辑
}
} finally {
// Lua脚本原子删除
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
redis.eval(script, Collections.singletonList(lockKey), Collections.singletonList(token));
}
☁️第三层:数据库缓存——最后的“安全气囊”
💡MySQL缓存优化秘籍:
- 查询缓存:开启
query_cache_type = DEMAND,对高频查询手动缓存 - 碎片整理:每周执行
OPTIMIZE TABLE,实测提升查询速度37% - 冷热分离:用TiDB将历史订单归档到低成本存储(每月节省40%成本)
🚨缓存治理“天龙八部”
- 大Key巡检:用
redis-cli --bigkeys自动报警(超过5MB立即拆分) - 热Key分散:用Consistent Hashing将“网红商品”分布到不同节点
- 穿透防护:布隆过滤器+空值缓存(设置5分钟过期)
- 混合存储:用Redis的向量搜索做推荐系统(某视频平台CTR提升22%)
📈2025年缓存技术风向标
- AI自适应TTL:根据数据访问模式动态调整过期时间
- 量子缓存预测:用D-Wave量子计算机预判热点数据(实验阶段)
- 新型持久化引擎:Redis 7.2版本写入速度再提升5倍
💡缓存不是“银弹”,但用好了就是“核武器”
记住这个黄金公式:
本地缓存(Caffeine) + 分布式缓存(Redis集群) + 数据库缓存(MySQL/TiDB) = 99.9%的请求在10ms内完成
下次遇到性能问题,先问自己:
“我的三级缓存体系搭好了吗?热Key都上锁了吗?大Key拆了吗?”

最后送大家一句真言:
“缓存用得好,下班回家早;缓存用得妙,CTO位置稳如老狗!” 🐶
本文由 小野寺智勇 于2025-08-03发表在【云服务器提供商】,文中图片由(小野寺智勇)上传,本平台仅提供信息存储服务;作者观点、意见不代表本站立场,如有侵权,请联系我们删除;若有图片侵权,请您准备原始证明材料和公证书后联系我方删除!
本文链接:https://vps.7tqx.com/fwqtj/526291.html
最新文章
-
CRM 新功能 Oracle发布托管型CRM R16,甲骨文推出全新客户关系管理平台功能
2025-08-06 -

网络安全🔒WiFi密码重设全攻略,轻松几步保护你的路由器
2025-08-06 -

策略必看🔥技巧满满🔥火锅不能停第1关保卫萝卜4详细通关攻略
2025-08-06 -

新手首选 极速上手CCTVBox下载技巧指南 软件下载速览】全流程解析,行业推荐必读
2025-08-06 -
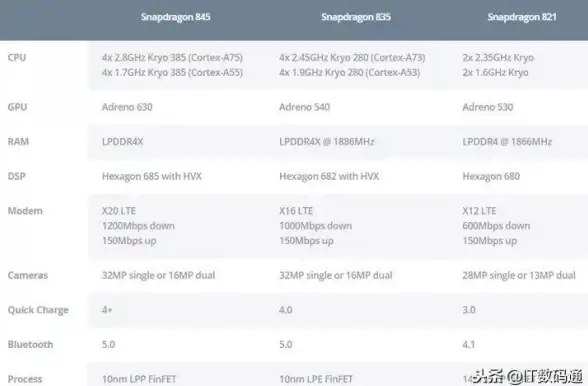
处理器排行📊性能对比|一文看懂CPU天梯图,详细对比主流处理器性能
2025-08-06 -
数据库管理 数据安全 Oracle 12c数据库备份方法详解,如何高效实现oracle12c备份数据库
2025-08-06 -

账号安全🔒交易指南🔥奥特曼宇宙英雄全攻略详解
2025-08-06 -
多运营商接入,大带宽组网-佛山机房多运营商大带宽网络部署难点解析
2025-08-06

发表评论