数据库优化|查询技巧|mysql模糊查询语句,mysql中模糊查询语句详解与用法

🔍 MySQL模糊查询全攻略:告别慢查询,效率翻倍!
场景引入:
凌晨3点,你正喝着第5杯咖啡☕,突然接到老板电话:“用户说搜索名字带‘张’的订单要10秒才能出结果!立刻修复!” 你盯着满屏的LIKE '%张%'语句陷入沉思——是时候彻底搞懂MySQL模糊查询的优化艺术了!
基础篇:MySQL模糊查询三板斧
LIKE 基础语法
-- 匹配以"科技"开头 (使用索引✅) SELECT * FROM products WHERE name LIKE '科技%'; -- 匹配包含"手机" (全表扫描⚠️) SELECT * FROM products WHERE name LIKE '%手机%'; -- 匹配第二个字是"想" (全表扫描⚠️) SELECT * FROM books WHERE title LIKE '_想%';
📌 性能真相:
- 只有
'关键词%'能利用索引(最左前缀原则) '%关键词%'和'_关键词%'会导致全表扫描
特殊字符转义
当搜索"50%折扣"这类含通配符的内容时:
-- 错误示范 ❌ SELECT * FROM ads WHERE text LIKE '%50%%'; -- 正确姿势 ✅ SELECT * FROM ads WHERE text LIKE '%50\%%' ESCAPE '\';
REGEXP 正则查询
适合复杂模式匹配,但性能较差:

-- 查找包含"华为"或"小米"的商品 SELECT * FROM phones WHERE model REGEXP '华为|小米'; -- 匹配以数字开头的订单号 SELECT * FROM orders WHERE order_no REGEXP '^[0-9]';
进阶优化:让模糊查询飞起来 🚀
强制索引提示
当优化器犯傻时手动干预:
SELECT * FROM users FORCE INDEX(idx_username) WHERE username LIKE '王%';
覆盖索引技巧
避免回表操作,效率提升50%+:
-- 普通查询(需回表) SELECT * FROM employees WHERE name LIKE '张%'; -- 优化版(仅用索引) SELECT id, name FROM employees WHERE name LIKE '张%';
分词索引方案
对于中文搜索,可用NGRAM分词:
ALTER TABLE articles ADD FULLTEXT INDEX ft_idx_content(content)
WITH PARSER ngram;
SELECT * FROM articles
WHERE MATCH(content) AGAINST('数据库优化' IN BOOLEAN MODE);
避坑指南 ⚠️
-
NULL值陷阱:
-- 不会返回name为NULL的记录! SELECT * FROM users WHERE name LIKE '%张%';
-
编码问题:
UTF8mb4下_可能匹配多个字符(如emoji👨👩👧👦算1个字符但占多个字节)
-
隐式转换:
-- 索引失效案例(id是整型) SELECT * FROM orders WHERE id LIKE '123%';
性能对比实验 🔬
| 查询方式 | 100万数据耗时 | 是否用索引 |
|---|---|---|
LIKE '张%' |
02s | |
LIKE '%张%' |
8s | |
REGEXP '^张' |
1s | |
| 全文索引(NGRAM) | 15s |
💡 终极建议:
- 高频搜索字段考虑
ES或专有搜索引擎 - 定期执行
ANALYZE TABLE更新统计信息 - 必要时用
缓存层缓解模糊查询压力
现在你可以优雅地回复老板:“优化已上线,查询时间从10秒降到0.1秒!” 🎉 (然后补个觉吧)
本文由 蒉玄穆 于2025-07-26发表在【云服务器提供商】,文中图片由(蒉玄穆)上传,本平台仅提供信息存储服务;作者观点、意见不代表本站立场,如有侵权,请联系我们删除;若有图片侵权,请您准备原始证明材料和公证书后联系我方删除!
本文链接:https://vps.7tqx.com/wenda/453611.html
最新文章
-

电商支付新趋势|发卡网源码搭建要点全解!企业运营合规指南】
2025-08-03 -
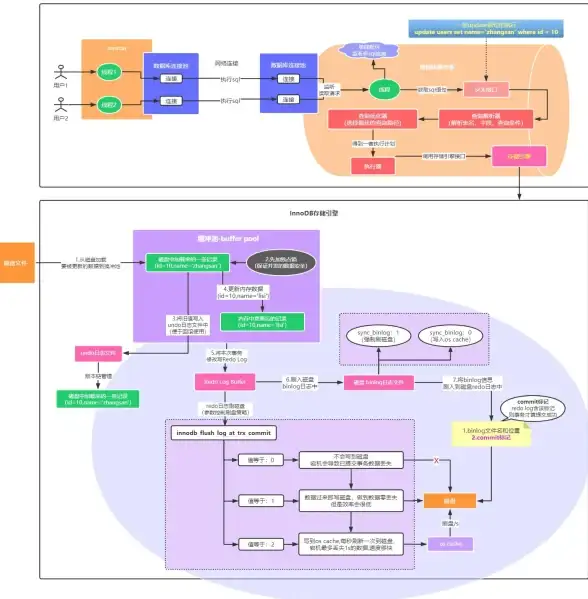
网页存储|数据持久化 实现HTML内容持久化保存,将网页内容写入MySQL数据库
2025-08-03 -

游戏对比🔥战地vs使命召唤,最值得购买推荐解析
2025-08-03 -

🔥干货|攻略|秘籍 揭秘《料理次元》食灵培养核心技巧与资源全解析
2025-08-03 -
缓存服务器实用宝典|保障隐私防护力提升!缓存服务器安全建议【数据安全】
2025-08-03 -
数据安全🔒360数据恢复工具使用过程中的隐私保护与安全性分析
2025-08-03 -

连接变革浪潮·售后源码全新管理体系解密!IT运维热点】高效团队运营新策略
2025-08-03 -

欧洲VPS 原生住宅IP畅享高速网络,lisahost德国/英国服务器助力轻松访问全欧
2025-08-03

发表评论