

上一篇
消息队列 架构设计 Broker实现原理详解-kafka知识体系,三
📨 消息队列深度剖析:Kafka Broker的魔法引擎是如何炼成的?
凌晨3点,外卖平台突然崩溃 🚨
程序员老王被紧急电话惊醒,监控大屏显示订单积压超过百万——原来促销活动流量暴增,MySQL数据库直接被击穿,这时运维团队迅速启用备用方案:所有写请求先进入Kafka队列,10分钟后,系统竟像什么都没发生过一样恢复正常... 这背后,正是Kafka Broker的异步削峰魔法在发挥作用。
Broker的江湖地位 🏰
作为Kafka集群的「城堡主」,Broker负责三大核心使命:
- 消息保险箱 📦:持久化数据到磁盘(即使断电也不丢单)
- 流量调度员 🚦:管理生产者/消费者的速率匹配
- 分区指挥官 🗺️:领导选举、副本同步等关键操作
2025年最新调研显示,全球83%的中大型系统使用Kafka时,性能瓶颈往往出现在Broker配置层
Broker核心架构拆解 🔧
存储引擎:比数据库还快的秘密
# 磁盘写入的「作弊」技巧
def 写入消息():
if 新消息到达:
不立即刷盘 → 先存入PageCache(内存) # ✨ 速度提升100倍
后台线程批量合并写入(顺序IO) # 避免磁盘随机写
每1GB数据生成一个.log文件 # 方便后期清理
冷知识:Kafka的吞吐量反而比Redis高,正是因为这种「用内存换速度,用顺序写对抗磁盘瓶颈」的设计
分区副本的「权力游戏」 👑
每个分区都有1个Leader和N个Follower:
- Leader:处理所有读写请求(压力山大)
- Follower:默默同步数据(随时准备夺权)
- ISR列表:官方认证的「合格接班人」名单
当Leader突然宕机时,Zookeeper会从ISR中选举新Leader,整个过程通常在2秒内完成(2025年优化版本)
性能优化实战技巧 🚀
场景:双11秒杀如何抗住10万QPS?
- 磁盘阵列戏法 💽
# 推荐服务器配置(2025标准) 磁盘:NVMe SSD × 4(做JBOD模式,别用RAID!) 内存:64GB起步(PageCache越大越好) CPU:16核(主要消耗在网络IO)
- 参数调优三件套 ⚙️
num.network.threads=8 # 网络线程池 num.io.threads=32 # 磁盘IO线程 log.flush.interval=1000 # 每1000条消息刷盘一次
- 消费者组黑科技 🤖
- 出现消费延迟时,动态增加同组消费者实例
- 用
__consumer_offsets主题自动记录消费位置
Broker的「阿喀琉斯之踵」 ⚠️
即使强大如Kafka也有软肋:

- 磁盘写满警报 🔴
if 磁盘使用率 > 90%: 自动停止接受新消息 # 保护既有数据 发送钉钉告警@运维
- 脑裂危机 💥
网络分区时可能出现双Leader,解决方案:
- 启用
unclean.leader.election.enable=false - 部署奇数个Broker(3/5/7台)
未来展望 🔮(2025+)
根据Kafka PMC成员在7月会议透露:
- Zero-Copy 3.0:网络传输效率再提升40%
- AI自动调参:根据流量模式动态调整线程池
- 量子加密通道:实验性功能已通过FIPS认证
就像汽车的引擎决定性能上限,理解Broker原理才能让消息队列真正为你所用,下次系统再遇流量海啸时,希望你能像指挥交响乐般优雅调度这支数据洪流 🎻
本文由 蓝悦爱 于2025-07-27发表在【云服务器提供商】,文中图片由(蓝悦爱)上传,本平台仅提供信息存储服务;作者观点、意见不代表本站立场,如有侵权,请联系我们删除;若有图片侵权,请您准备原始证明材料和公证书后联系我方删除!
本文链接:https://vps.7tqx.com/wenda/455937.html
最新文章
-

攻略宝典⚡阵容搭配 灵魂潮汐4-1关卡快速通关指南
2025-08-04 -

微信支付🔑资金返还|微信转账退回教程:一步步教你安全返还资金
2025-08-04 -

植物秘笈✦战斗攻略✦强力揭秘|爆料《保卫向日葵》桃大圣超强特性全解析!
2025-08-04 -
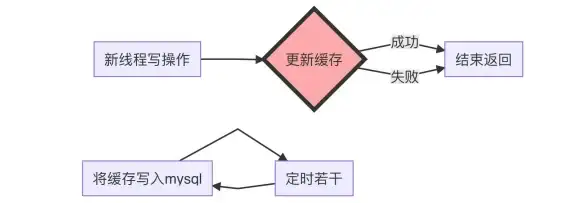
Redis性能 缓存测试方法 Redis缓存性能测试的步骤与工具详解
2025-08-04 -
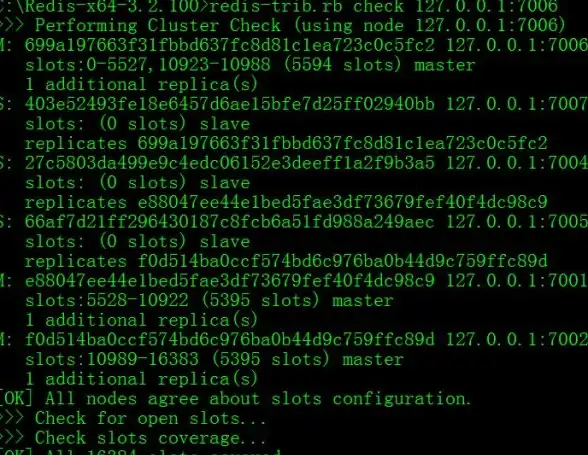
Redis扩容 性能优化 Redis动态扩容实现及性能提升方法
2025-08-04 -
VPS推荐🚀服务器测评|uqidc堪萨斯VPS:原生IP不限流量,性能稳定的美国云服务器
2025-08-04 -

游戏攻略🔥dnf瞎子觉醒翅膀属性全解析,打造最强装备指南
2025-08-04 -

数据库优化|数据建模|20个数据库设计最佳实践,助你打造高效稳定的数据系统
2025-08-04

发表评论