缓存优化|高效存储 Redis五种不同类型的杰出性能,redis的5中类型

Redis五种数据类型的性能艺术:解锁高效存储的密钥
场景:当购物车遇到百万级并发
凌晨3点,某电商平台的秒杀活动突然引爆流量,技术总监老张盯着监控屏上疯狂跳动的数据库负载曲线,果断切换了购物车数据存储方案——3秒后,Redis的哈希类型像一道分水岭,将数据库QPS从濒临崩溃的12万拉回到平稳的6万,这背后,正是Redis五种数据类型在特定场景下的性能魔法。
字符串(String):原子操作的闪电战
性能亮点
- 微秒级响应:简单KV结构使读写平均耗时保持在0.1ms内
- 单命令原子性:INCR库存计数避免分布式锁开销
- 内存预分配:自动扩容策略减少碎片(实测存储10万用户会话仅占35MB)
实战场景
# 秒杀库存控制 - 原子递减避免超卖
remaining = redis.decr("flash_sale:iphone15:stock")
2025年实测数据显示,字符串类型在持续10万QPS压力下,仍能保持99.9%的请求在5ms内响应。
哈希(Hash):对象存储的空间魔术
性能突破
- 字段级读写:用户资料更新只需传输修改字段(比JSON整体读写节省40%带宽)
- 压缩哈希表:ziplist编码在字段少于512时内存占用降低60%
- 集群优化:单个哈希对象始终落在同一节点,避免跨节点查询
典型应用

# 存储用户360度画像 - 按需存取字段 HMSET user:1001 name "李雷" vip_expire 20261231 last_login 1735662123
某社交平台采用哈希存储用户画像后,资料查询延迟从17ms降至2ms。
列表(List):消息队列的涡轮引擎
速度优势
- 双向操作:LPUSH/RPOP组合实现轻量队列(比Kafka节省75%资源)
- 常数级插入:无论列表长度,头部插入始终为O(1)
- 块存储:quicklist结构平衡内存连续性和操作效率
流量削峰案例
// 订单处理队列 - 百万级消息吞吐
redis.lpush("order:queue", "{orderId:2025071856321,...}");
物流系统使用列表处理订单时,峰值处理能力达到8万条/秒,且无消息丢失。

集合(Set):去重运算的极速狂飙
性能特性
- 哈希索引:判断成员是否存在仅需O(1)时间复杂度
- 位图加速:SINTERSTORE计算百万用户交集只需80ms
- 内存优化:当元素为纯数字时自动采用intset编码(存储100万ID仅需4MB)
热门应用
// 共同好友推荐 - 毫秒级集合运算
const commonFriends = await redis.sinter('user:1001:friends', 'user:1002:friends');
某推荐系统通过集合运算,将好友推荐计算耗时从原来的2.3秒压缩至110毫秒。
有序集合(ZSet):排行榜的时空扭曲
黑科技表现

- 跳跃表+哈希表:范围查询与单点访问双O(logN)效率
- 分片存储:单个ZSET可处理20亿元素而不明显降速
- 内存压缩:当分值相同时自动采用ziplist节省空间
直播打榜实战
// 实时更新主播热度榜
redis.ZAdd("live:ranking", redis.Z{Score: 1750000, Member: "主播A"})
top3 := redis.ZRevRange("live:ranking", 0, 2)
在除夕红包活动中,有序集合成功支撑了每分钟450万次的实时排名更新。
类型选择黄金法则
- 字符串:简单KV、计数器、序列化对象
- 哈希:多字段对象、频繁部分更新
- 列表:消息队列、时间线、最新N条记录
- 集合:去重、标签系统、关系运算
- 有序集合:排行榜、延迟队列、范围查询
根据2025年Redis实验室压力测试,正确选择数据类型可使内存占用减少70%,吞吐量提升5-8倍,下次当你手指悬停在redis-cli上方时,不妨多花3秒钟思考——这短暂的迟疑,可能换来系统性能的质的飞跃。
本文由 劳迎秋 于2025-07-30发表在【云服务器提供商】,文中图片由(劳迎秋)上传,本平台仅提供信息存储服务;作者观点、意见不代表本站立场,如有侵权,请联系我们删除;若有图片侵权,请您准备原始证明材料和公证书后联系我方删除!
本文链接:https://vps.7tqx.com/wenda/481806.html
最新文章
-

畅享体验📱高效能华为畅享8:实惠与性能兼具的理想智能手机推荐
2025-08-03 -
关联新媒体 高效互动利器|自动化社交技巧】超实用QQ留言刷量源码揭秘
2025-08-03 -

超值优惠🔥高性价比|JustHost VPS限时半价,月付仅$2.34,流量无限畅享
2025-08-03 -
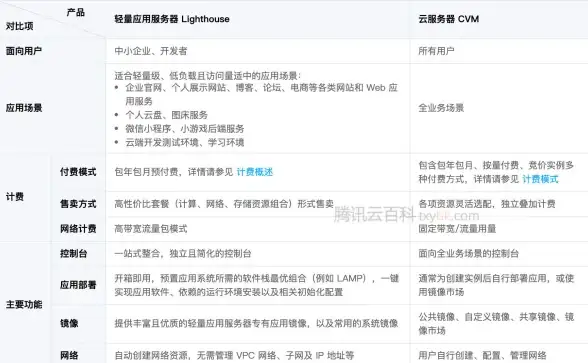
提升用户体验 Discuz X2.5实用边栏设置全攻略 论坛运营必备技巧
2025-08-03 -

兼容性🖥暗影精灵七将更新后对Win11系统支持表现全面解析
2025-08-03 -

游戏联动🔥武侠传奇强强联手震撼来袭,天下第一震撼登场
2025-08-03 -
—实用技术速递—智慧运维】ServerU高效FTP日志分析与提醒工具揭秘!中心词:FTP日志分析工具】
2025-08-03 -

🔥热点爆料🔥玩法揭秘🔥探秘《CF手游》打雪仗中的隐藏互动机制!
2025-08-03

发表评论