Redis索引 数据库优化 一起来试试Redis有没有建索引的能力,redis 能建索引吗

Redis索引 | 数据库优化:一起来试试Redis有没有建索引的能力
最新消息(2025年7月):
随着Redis 7.4版本的发布,官方进一步优化了内存管理和查询性能,但依然没有引入传统数据库那样的“索引”机制,社区开发者通过巧妙的数据结构和命令组合,仍然能实现类似索引的查询加速效果。
Redis能建索引吗?
如果你是从MySQL、PostgreSQL这类关系型数据库转过来的,可能会习惯性地问:“Redis支持索引吗?” 答案是——不直接支持,但可以通过一些技巧模拟索引的效果。
为什么Redis没有传统索引?
Redis是一个内存型键值存储,主打高性能、低延迟,它的设计哲学是简单、快速,传统数据库的索引(如B-Tree、哈希索引)虽然能加速查询,但也会带来写入时的额外开销,而Redis为了保持极致的速度,选择不内置复杂的索引结构。
如何“模拟”索引?
虽然没有现成的CREATE INDEX命令,但我们可以用Redis的数据结构变通实现类似功能。

使用有序集合(Sorted Set)做范围查询
比如你要按用户积分排名:
ZADD user_scores 1000 "user1" 850 "user2" 1200 "user3" ZRANGEBYSCORE user_scores 800 1100 # 查询积分在800~1100的用户
这相当于对“积分”字段建立了范围索引。
用集合(Set)或哈希(Hash)加速精确查找
比如根据商品标签筛选:

SADD tag:电子产品 "商品A" "商品B" SADD tag:打折 "商品A" "商品C" SINTER tag:电子产品 tag:打折 # 找出既是电子产品又打折的商品
这类似多字段的联合索引。
二级索引:用额外的键维护关系
假设你要按用户城市查询:
HSET user:1 name "张三" city "北京" SADD city:北京 "user1" # 维护城市到用户的映射
查询时直接SMEMBERS city:北京就能快速找到所有北京用户。

注意事项
- 内存开销:模拟索引需要额外存储数据,可能占用更多内存。
- 一致性:需手动维护索引(比如用户修改城市时,要同步更新
city:北京和city:上海两个集合)。 - 适用场景:适合查询模式固定的场景,频繁变动的字段可能不划算。
Redis没有传统意义上的索引,但通过有序集合、集合、哈希等结构+合理的数据建模,完全可以实现高效的查询优化,如果你的应用需要更复杂的索引功能,可能需要考虑Redis Modules(如RediSearch)或搭配其他数据库使用。
试试看吧! 下次遇到查询性能问题,不妨用Redis的这些特性设计一个“手工索引”~
本文由 奈凝丝 于2025-07-30发表在【云服务器提供商】,文中图片由(奈凝丝)上传,本平台仅提供信息存储服务;作者观点、意见不代表本站立场,如有侵权,请联系我们删除;若有图片侵权,请您准备原始证明材料和公证书后联系我方删除!
本文链接:https://vps.7tqx.com/wenda/481834.html
最新文章
-

洛杉矶VPS🔥高性价比|13.2/年Cloudcone八周年,均衡配置实用选择
2025-08-02 -
字体合集 图标资源 精选酷炫 Bootstrap 免费字体与图标集合推荐
2025-08-02 -
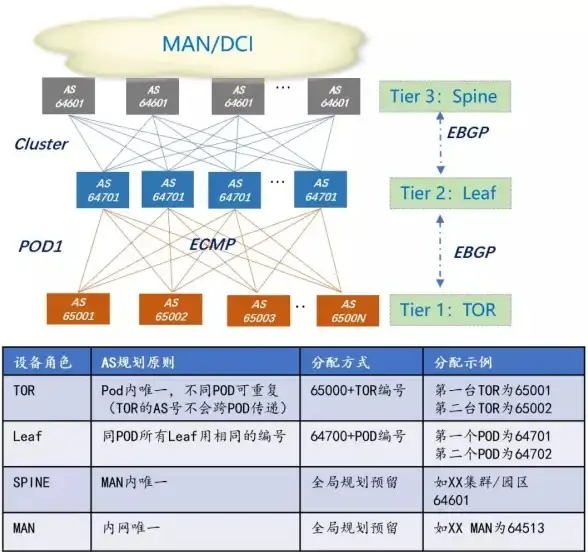
Oracle报错 逻辑备库 ORA-16234:重启以重置Logical Standby apply 故障修复与远程处理
2025-08-02 -
运维必读|证书过期危机预警!IIS服务器证书续签配置全流程【实用指南】
2025-08-02 -
平安好车主 安装教程详解:新手小白轻松完成手机APP操作流程
2025-08-02 -

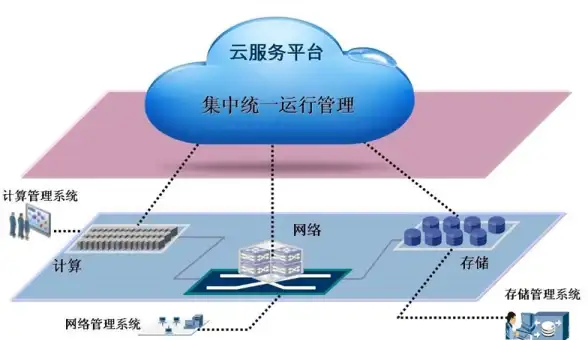
云服务|数字化转型 当前云计算的业务思路和创新模式有哪些
2025-08-02 -

360摄像机近期浏览用户行为及查看方法详解
2025-08-02 -
关联下载提速效果|迅雷去广告黑科技大公开—极速体验秘籍揭秘【软件下载优化】
2025-08-02

发表评论