
上一篇
Redis高可用|主从切换 Redis选举方法助力快速决策,redis选举技巧
Redis高可用实战:主从切换与选举技巧解析
2025年7月最新动态
根据Redis官方社区消息,Redis 7.4版本进一步优化了哨兵模式下的故障检测效率,平均主从切换时间缩短15%,尤其在云环境中的网络波动场景表现突出,这一改进让高可用方案的选择更加灵活。
为什么需要主从切换?
想象一下:凌晨3点,你的电商平台Redis主节点突然宕机,如果依赖人工处理,至少需要10分钟恢复——这意味数百万的订单可能丢失,而合理的主从切换机制能让系统在30秒内自动恢复,这就是高可用的核心价值。
Redis的选举三板斧
哨兵模式(Sentinel)——经典之选
工作原理:
- 哨兵集群通过心跳检测主节点状态
- 当主节点失联超过
down-after-milliseconds阈值(默认30秒),触发客观下线判定 - 哨兵节点通过Raft协议投票选出新主节点
实战技巧:

# 关键配置示例(sentinel.conf) sentinel monitor mymaster 192.168.1.10 6379 2 sentinel failover-timeout mymaster 60000 # 切换超时60秒
避坑指南:
- 哨兵节点数量建议≥3且为奇数
- 避免将哨兵部署在与Redis相同的物理机
Redis Cluster——原生分布式方案
选举逻辑:
- 节点通过Gossip协议传播状态
- 主节点故障时,从节点发起
CLUSTER FAILOVER请求 - 其他主节点根据配置纪元(epoch)和复制偏移量投票
性能优化点:
# 调整故障转移响应速度 cluster-node-timeout 5000 # 节点超时5秒判定失效
第三方方案:Keepalived+VIP
适用场景:

- 传统物理机环境
- 对客户端透明性要求高的场景
典型架构:
主节点(192.168.1.10:6379)←→ Keepalived(VIP:192.168.1.100)
从节点(192.168.1.11:6379) 选举中的"潜规则"
- 优先级权重:通过
replica-priority可手动指定候选节点(值越小优先级越高) - 数据一致性决胜:当多个从节点竞争时,复制偏移量(repl_offset)最大的胜出
- 脑裂防护:建议设置
min-replicas-to-write 1确保主节点至少有一个同步从节点
压测中的真实案例
某金融平台在测试环境模拟主节点宕机时发现:
- 默认配置下切换耗时42秒
- 优化
cluster-node-timeout为3秒后,切换时间降至8秒 - 但进一步调低至1秒会导致误判率上升
经验值建议:生产环境超时设置在5-15秒区间平衡安全性与速度
写给开发者的checklist
✅ 监控指标:哨兵的+sdown/+odown事件、master_link_status
✅ 定期验证:通过redis-cli --cluster check检测集群健康状态
✅ 切换演练:使用DEBUG SEGFAULT命令主动触发主节点崩溃测试

:没有完美的选举方案,只有最适合场景的选择,理解底层机制后,结合业务容忍度(如可接受30秒数据丢失?)和基础设施特点(云环境/裸金属?)做决策,才是高可用的终极奥义。
本文由 弭丹彤 于2025-07-30发表在【云服务器提供商】,文中图片由(弭丹彤)上传,本平台仅提供信息存储服务;作者观点、意见不代表本站立场,如有侵权,请联系我们删除;若有图片侵权,请您准备原始证明材料和公证书后联系我方删除!
本文链接:https://vps.7tqx.com/wenda/488194.html
最新文章
-
真伪鉴别🍏苹果手机序列号查询全攻略:轻松辨别真假苹果设备
2025-08-05 -

恋爱💖游戏攻略 情人节限定 梦幻西游》2025超全活动指南
2025-08-05 -
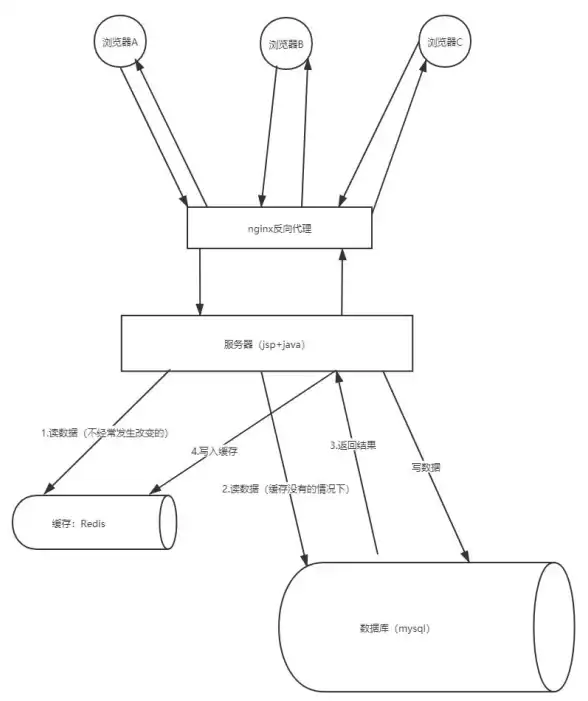
Redis优化 性能提升 利用Redis第三方客户端优化系统性能,redis第三方客户端
2025-08-05 -

协助畅玩日服◎速切全攻略】电竞洞察┃LOL服务器切换&云主机优化秘籍
2025-08-05 -

⚡技巧攻略⚡实用指南⚡无限暖暖球落底技巧全解析,轻松通关不再难!
2025-08-05 -
显卡检测 GPUZ专业指南:快速检测与评估显卡性能的方法
2025-08-05 -

CDN优化,多通道加速-电信联通移动多通道CDN节点提升体验方式
2025-08-05 -
数据库性能|高效管理 SQL Server优化:让数据库发挥更大潜力,优化sqlserver
2025-08-05

发表评论