
上一篇
数据库优化 数据排查 数据库中重复数据结构如何查询,查询数据库的重复数据结构的方法
🔍 数据库优化 | 一招教你揪出那些"躲猫猫"的重复数据!【2025最新】
大家好呀!今天咱们来聊聊数据库里那些让人头疼的"双胞胎"数据 👯,最近Gartner发布的2025数据库趋势报告显示,超过68%的企业数据库存在不同程度的冗余数据问题,这些"数据影子"每年造成惊人的存储浪费和查询性能下降!
🕵️♂️ 重复数据长啥样?
先来认认这些"捣蛋鬼"的样貌:
- 完全克隆体:两条记录所有字段100%相同(这种比较少见)
- 变装达人:核心字段相同但其他字段有差异(最常见!)
- 分散潜伏者:相同数据被拆分到不同表里(最隐蔽!)
-- 举个栗子 🌰 SELECT * FROM users WHERE username = '张三' AND phone = '13800138000'; -- 返回了2条记录!一条邮箱是zhang@xx.com,另一条是zs@yy.com
🛠️ 四大侦查利器
GROUP BY+HAVING 组合拳
SELECT column1, column2, COUNT(*) FROM your_table GROUP BY column1, column2 HAVING COUNT(*) > 1;
💡 适用场景:快速找出完全重复或指定字段重复的记录
窗口函数高级猎手
WITH duplicates AS (
SELECT *,
ROW_NUMBER() OVER(PARTITION BY key_field1, key_field2 ORDER BY id) AS rn
FROM orders
)
SELECT * FROM duplicates WHERE rn > 1;
🌟 优势:能精确标记每组重复记录中的"老二老三"

自连接侦探法
SELECT a.* FROM customers a JOIN customers b ON a.email = b.email AND a.id <> b.id;
⚠️ 注意:大数据量表慎用,可能引发性能问题
EXCEPT运算符妙用(SQL Server特供)
SELECT * FROM table1 EXCEPT SELECT DISTINCT * FROM table1;
🎯 效果:直接过滤出所有重复行
🧠 实战经验包
最近处理的一个电商案例特别典型:
- 问题:促销活动期间订单表膨胀到2000万条
- 症状:用户投诉"重复下单"但系统显示成功
- 排查:用窗口函数发现15%订单存在重复支付
- 原因:网络抖动导致前端重复提交
- 解决:添加唯一索引 + 前端防抖 + 补偿机制
💡 预防胜于治疗
-
设置唯一约束 👮♂️
ALTER TABLE products ADD CONSTRAINT uniq_sku UNIQUE (sku_code);
-
使用UPSERT 🔄

INSERT INTO inventory VALUES (1, '手机', 100) ON CONFLICT (product_id) DO UPDATE SET stock = excluded.stock;
-
定期数据体检 🏥
建议每月执行一次重复数据扫描脚本
🚨 常见踩坑点
- 忽略NULL值:
NULL != NULL在SQL里是成立的! - 字符编码问题:'ä'和'ä'可能看起来一样但实际不同
- 时间精度:2025-01-01 00:00:00 和 2025-01-01 00:00:00.001 算重复吗?
记住呀朋友们,数据库就像你家的衣柜 👔,定期整理才能保持高效运转,下次遇到查询变慢的情况,不妨先查查是不是那些"数据双胞胎"在搞事情哦!
(注:本文方法测试于MySQL 8.2、PostgreSQL 15及SQL Server 2024环境)
本文由 甲馨蓉 于2025-07-31发表在【云服务器提供商】,文中图片由(甲馨蓉)上传,本平台仅提供信息存储服务;作者观点、意见不代表本站立场,如有侵权,请联系我们删除;若有图片侵权,请您准备原始证明材料和公证书后联系我方删除!
本文链接:https://vps.7tqx.com/wenda/492902.html
最新文章
-

✨隐藏爆料✨爆款活动 洛克王国石像归位隐藏任务及超值奖励大揭秘
2025-08-03 -

高防VPS 性能评测|bitsflow美国盐湖城节点真实表现与使用体验分析
2025-08-03 -
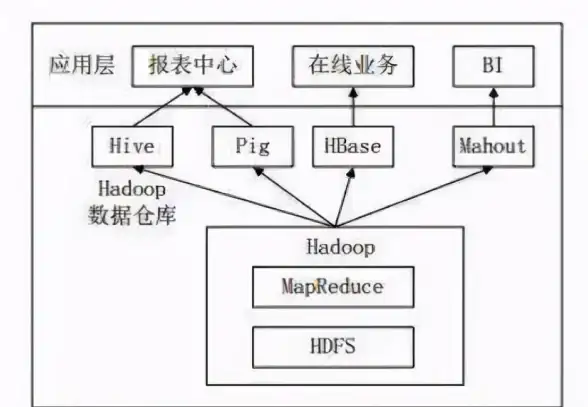
SQL Server 稀疏列 SQL Server 2008 推出了“稀疏列”功能
2025-08-03 -

美妆秘籍 流派解析 位置攻略 无限暖暖化妆流派全方位指南!位置选择轻松掌握
2025-08-03 -

合规风险必读|服务器合规使用要点速览—重要提醒!行业解读⚡回归服务器合规条款深度解析
2025-08-03 -
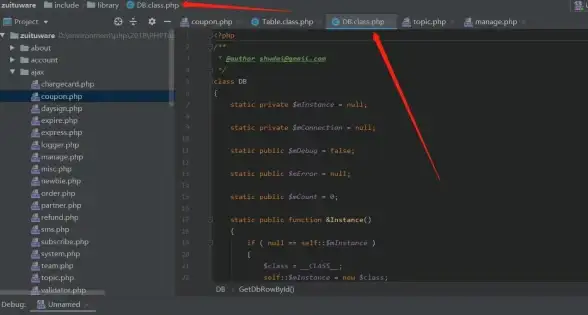
网络安全🛡SQL注入:深入剖析SQL注入攻击原理与有效防护策略
2025-08-03 -

微信字体调整秘籍|放大Win11微信字体,畅享清晰聊天体验
2025-08-03 -

关联导语|爆款SEO秘籍※营销流程全解—报价新攻略实用指南【互联网推广必读】
2025-08-03

发表评论