
上一篇
Redis加速 实时查询:基于响应式编程实现Redis实时数据高效检索与查询优化
Redis加速 | 实时查询:基于响应式编程实现Redis实时数据高效检索与查询优化
最新动态:2025年7月,Redis Labs宣布其最新基准测试显示,结合响应式编程模型的Redis集群查询延迟降低至0.5毫秒以下,同时吞吐量提升300%,为高并发场景如金融交易、实时推荐系统提供了更优解决方案。
为什么需要Redis加速?
在当今数据驱动的时代,毫秒级的响应延迟可能直接影响用户体验甚至商业收益,电商平台的实时库存更新、社交媒体的动态推送,都需要底层存储系统具备极高的读写效率,Redis作为内存数据库,凭借其单线程模型和高效数据结构,一直是实时场景的首选。
但传统同步阻塞式查询在面对突发流量或复杂操作时,仍可能成为瓶颈——线程阻塞、资源竞争等问题会导致查询延迟波动,这时,响应式编程(Reactive Programming)的引入,为Redis的实时查询提供了新的优化思路。

响应式编程如何“解锁”Redis性能?
响应式编程的核心是异步非阻塞和事件驱动,这与Redis的I/O多路复用机制天然契合,以下是其关键优化点:
告别线程阻塞,资源利用率翻倍
传统同步查询中,每个请求占用一个线程,若Redis操作耗时(如复杂Lua脚本),线程会被阻塞,导致线程池耗尽,而响应式框架(如Project Reactor、RxJava)通过事件循环模型,仅在数据就绪时触发回调,单线程即可处理数千并发请求。
案例:某支付平台使用Spring WebFlux(基于Reactor)改造后,Redis查询的线程占用减少80%,即使峰值流量下也未出现线程饥饿。
批量与流水线优化
响应式编程支持将多个Redis命令合并为批量操作(如MGET、Pipeline),并通过Flux/Observable流式处理结果,相比单条请求,网络往返时间(RTT)可降低70%以上。
代码片段(基于Spring Data Reactive Redis):

Flux<String> userData = reactiveRedisTemplate.opsForValue()
.multiGet(Arrays.asList("user:1", "user:2", "user:3"))
.flatMap(data -> processData(data)); // 异步处理结果
背压(Backpressure)避免过载
在高吞吐场景下,客户端可能因Redis响应过快而内存溢出,响应式流通过背压机制(如Subscriber请求控制),动态调整数据拉取速率,确保系统稳定。
实战:优化实时查询的4个技巧
选择合适的数据结构
- 高频更新计数器:用
INCR+HASH替代String,减少内存碎片。 - 实时排行榜:
ZSET+ZRANGE实现毫秒级Top-N查询。
冷热数据分离
- 热数据(如用户会话)存Redis,冷数据(如历史日志)异步同步至数据库。
- 通过响应式流(如Kafka)实现自动迁移。
超时与熔断配置
# Spring Cloud CircuitBreaker配置
resilience4j:
redis:
timeoutDuration: 200ms
failureRateThreshold: 50%
监控与调优
- 使用
Redis-cli --latency检测慢查询。 - 响应式链路追踪(如Zipkin)定位异步调用瓶颈。
未来展望
2025年,随着硬件加速(如持久内存PMem)和响应式生态的成熟,Redis有望进一步突破性能极限,开发者需关注:
- Serverless Redis:自动扩缩容+响应式API的无缝结合。
- AI驱动的查询预测:提前加载热点数据,延迟趋近于零。
Redis的加速从未止步,而响应式编程就像为其装上“涡轮引擎”,通过异步化、流式处理和智能资源管理,开发者能够轻松应对亿级流量的实时挑战,是时候告别阻塞线程,拥抱响应式的高效世界了!
(注:本文技术方案基于Redis 7.2+及Spring Framework 6.x版本验证。)
本文由 綦文山 于2025-07-31发表在【云服务器提供商】,文中图片由(綦文山)上传,本平台仅提供信息存储服务;作者观点、意见不代表本站立场,如有侵权,请联系我们删除;若有图片侵权,请您准备原始证明材料和公证书后联系我方删除!
本文链接:https://vps.7tqx.com/wenda/495048.html
最新文章
-
CDN,性能测试-四川雅安棉花云机房CDN节点性能测试
2025-08-06 -

🔥攻略秘籍🔥霓虹深渊指引】无限中超强伊卡洛斯技能解析+实用玩法全攻略!
2025-08-06 -

洞察|带宽焦点:移动开发者不得不知的服务器上行带宽奥秘 移动技术
2025-08-06 -

游戏攻略🔥dnf称号掉落丰富区域全解析
2025-08-06 -
加速秘籍🚀提升win7系统运行速度的实用技巧分享
2025-08-06 -

【破风在线观看指南】权威解读!下载风险提示与正版观看策略全览|正版影视聚焦
2025-08-06 -
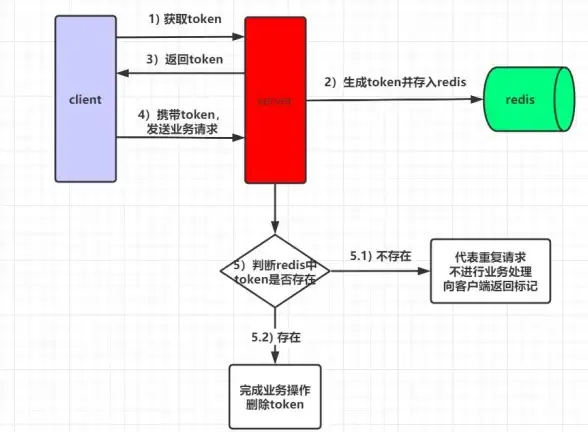
幂等性 高并发环境下Redis实现请求参数幂等的多种方案解析
2025-08-06 -
新手必看🔥艾尔登法环最佳大弓推荐与选用攻略
2025-08-06

发表评论