
上一篇
数据库 数据缓冲区 聊聊 OB 的缓冲区机制,你明白了吗?
数据库 | 数据缓冲区:聊聊 OB 的缓冲区机制,你明白了吗?💡
📢 最新消息(2025年7月)
OceanBase(OB)在最新的 5.0 版本中优化了缓冲区管理机制,进一步提升了高并发场景下的性能表现,内存利用率提高了约15%!这对于企业级数据库用户来说是个不小的福音🎉。
什么是数据缓冲区?🤔
数据缓冲区(Buffer Pool)就是数据库的“临时记忆库”🧠,它是一块内存区域,用来缓存磁盘上的数据页,减少直接访问磁盘的次数,从而大幅提升查询和写入速度。
想象一下,如果你每次查数据都要翻硬盘(就像每次吃饭都跑超市),那得多慢啊!而缓冲区就像是你的“冰箱”,把常用的数据先存起来,随取随用🍎。
OB 的缓冲区机制有什么特别?🚀
OceanBase(OB)作为一款分布式数据库,它的缓冲区设计比传统数据库(MySQL)更复杂,但也更高效,主要特点包括:
多级缓存策略
OB 的缓冲区不是简单的一块内存,而是分层管理:

- MemTable:存储最新的写入数据(内存表)。
- Block Cache:缓存数据块,加速读取。
- Row Cache(可选):缓存热点行数据,适合频繁访问的场景。
这种分层设计让 OB 能更灵活地利用内存,避免“一刀切”导致的浪费或不足。
智能淘汰算法
OB 默认使用 LRU(最近最少使用) 策略来管理缓存,但还结合了冷热数据分离机制:
- 频繁访问的“热数据”会保留更久❄️→🔥。
- 长期不用的“冷数据”会被优先淘汰,腾出空间给新数据。
分布式协同缓存
在 OB 的分布式架构中,每个节点都有自己的缓冲区,但它们会通过一致性协议协同工作,避免重复缓存,提高整体内存利用率。
缓冲区太小会怎样?太大又会怎样?⚠️
❌ 缓冲区太小
- 频繁的磁盘 I/O,性能下降(就像电脑卡成PPT)。
- 查询延迟变高,尤其是复杂查询。
❌ 缓冲区太大
- 占用过多内存,可能影响其他业务进程。
- 如果数据更新频繁,还可能引发“缓存抖动”(频繁换入换出,反而拖慢速度)。
✅ 如何设置合理大小?
OB 官方建议:

- 初始值设为可用内存的 50%~70%。
- 观察实际负载调整,比如监控
buffer pool hit rate(命中率),理想值应 >95%。
实战技巧:如何优化 OB 缓冲区?🔧
-
监控关键指标
buffer_pool_hit_ratio:命中率低说明缓存不够。disk_reads_per_second:磁盘读取频率高可能是缓存不足的信号。
-
调整参数
ALTER SYSTEM SET buffer_pool_size='32G'; -- 调整缓冲区大小
-
预热缓存
重启后缓存是空的?可以手动加载热点数据:SELECT * FROM hot_table WHERE id IN (1,2,3...); -- 主动触发缓存加载
🎯
OB 的缓冲区机制就像数据库的“加速引擎”🚄,合理配置能极大提升性能。

- 分层缓存 + 智能淘汰 = 高效内存利用。
- 监控命中率,避免“太小”或“太大”。
- 分布式环境下,协同缓存是关键!
还没搞懂?评论区见!👇 或者自己动手调个参数试试,感受下速度变化吧~ 🏎💨
📅 信息参考:OceanBase 官方文档(2025年7月更新)
本文由 伏旋 于2025-07-31发表在【云服务器提供商】,文中图片由(伏旋)上传,本平台仅提供信息存储服务;作者观点、意见不代表本站立场,如有侵权,请联系我们删除;若有图片侵权,请您准备原始证明材料和公证书后联系我方删除!
本文链接:https://vps.7tqx.com/wenda/495644.html
最新文章
-
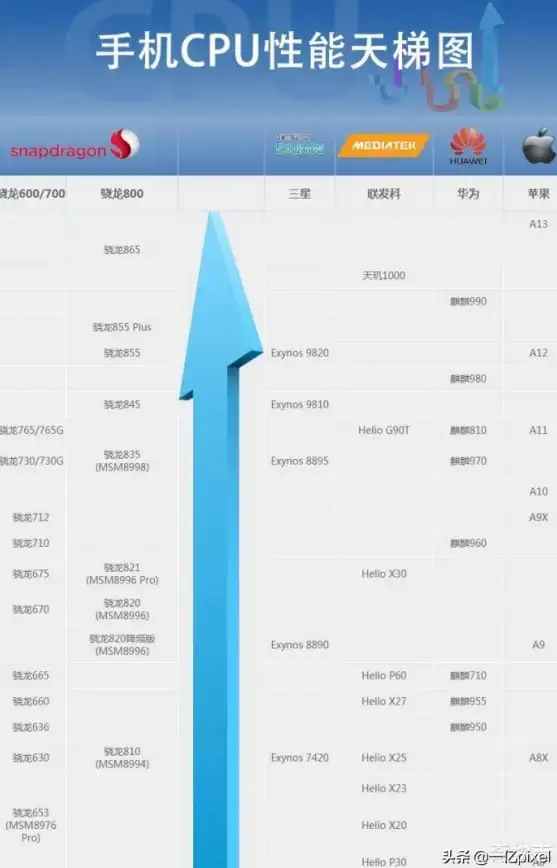
AI芯片🚀性能芯片天梯图8月全新解析:深度解读主流芯片表现与行业发展趋势
2025-08-04 -
装备大揭秘⚡属性解析⚡地下城勇士装备材质转换全面解析!
2025-08-04 -
键盘故障🚀遇到键盘错乱别慌,小鱼带你快速解决问题
2025-08-04 -

洛杉矶服务器🚀网络加速器|高速、稳定、低价,洛杉矶VPS,AMD+GIA的完美搭档
2025-08-04 -

攻略指南🔥怪物猎人手柄R2键全方位功能详解揭秘
2025-08-04 -

Redis应用 数据库开发 Redis自定义数据库实现之路,探索redis自定型技术
2025-08-04 -
企业数据守护 空间合规洞察—聚焦微软服务器安全新提醒★实用操作技巧【数据合规要点】
2025-08-04 -

配置技巧 实用秘籍集锦 IE代理服务器安全防护】ieapp代理配置全方位详解
2025-08-04

发表评论