
上一篇
Redis缓存 点赞系统 利用Redis高效管理点赞数据,实现点赞信息的快速存储与读取,redis 点赞数据存储
Redis缓存助力点赞系统:高效管理海量点赞数据 💖
场景引入:当点赞遇上高并发
"叮咚~" 你的手机又响了,是小红书的点赞通知?还是抖音上的新喜欢?在这个全民互动的时代,一个爆款内容可能在几秒内收到成千上万的点赞,想象一下,如果每次点赞都要直接写入数据库,那数据库岂不是要"爆炸"了?💥
别担心,Redis这位"数据闪电侠"🦸♂️正是解决这个问题的绝佳方案!让我们一起来看看如何用Redis高效管理点赞数据。
为什么选择Redis管理点赞数据?
- 闪电速度 ⚡:Redis基于内存操作,读写速度可达10万+/秒,完美应对高并发点赞
- 数据结构丰富 🧩:提供String、Hash、Set、Sorted Set等多种结构,点赞场景灵活适配
- 持久化保障 🔒:虽然基于内存,但支持RDB和AOF持久化,不怕断电丢数据
- 原子操作 ⚛️:单线程模型保证操作原子性,点赞计数准确无误
Redis点赞系统核心设计
点赞数据存储方案
String结构(简单计数)
SET post:like:count:12345 8567
# 用户点赞记录(1表示已点赞)
SET user:like:789:post:12345 1👍 适合:只需要点赞总数的简单场景

Hash结构(用户级记录)
HSET post:likes:12345 user789 "2025-07-15T14:30:00" user456 "2025-07-15T14:31:00"
# 用户点赞的内容记录
HSET user:likes:789 post12345 "2025-07-15T14:30:00" post67890 "2025-07-16T09:15:00"👍 适合:需要记录详细点赞信息的场景
Set结构(去重点赞)

SADD post:liked_users:12345 789 456 123
# 用户点赞内容集合
SADD user:liked_posts:789 12345 67890👍 适合:需要快速判断是否已点赞的场景
点赞系统架构设计
用户点击点赞 → 前端请求 → API网关 → Redis缓存层 → (异步) → 数据库持久化关键点:
- 先写Redis,确保快速响应
- 通过消息队列异步同步到数据库
- 定时任务补偿可能的数据不一致
实战代码示例(Python版)
import redis
from datetime import datetime
# 连接Redis
r = redis.Redis(host='localhost', port=6379, db=0)
def like_post(user_id, post_id):
"""用户点赞"""
# 检查是否已点赞
if r.sismember(f"post:liked_users:{post_id}", user_id):
return False
# 记录点赞关系
pipeline = r.pipeline()
pipeline.sadd(f"post:liked_users:{post_id}", user_id)
pipeline.sadd(f"user:liked_posts:{user_id}", post_id)
pipeline.hset(f"post:likes:{post_id}", user_id, datetime.now().isoformat())
pipeline.incr(f"post:like:count:{post_id}")
pipeline.execute()
return True
def unlike_post(user_id, post_id):
"""用户取消点赞"""
# 检查是否已点赞
if not r.sismember(f"post:liked_users:{post_id}", user_id):
return False
# 移除点赞关系
pipeline = r.pipeline()
pipeline.srem(f"post:liked_users:{post_id}", user_id)
pipeline.srem(f"user:liked_posts:{user_id}", post_id)
pipeline.hdel(f"post:likes:{post_id}", user_id)
pipeline.decr(f"post:like:count:{post_id}")
pipeline.execute()
return True
def get_like_count(post_id):
"""获取点赞总数"""
return int(r.get(f"post:like:count:{post_id}") or 0)
def has_liked(user_id, post_id):
"""检查用户是否已点赞"""
return r.sismember(f"post:liked_users:{post_id}", user_id)
高级优化技巧 🚀
- 热点数据处理:对于爆款内容,可以使用Redis集群分片减轻单节点压力
- 内存优化:对于大V用户,可以定期归档历史点赞数据
- 二级缓存:结合本地缓存减少Redis访问
- 数据预热提前加载到Redis
- 过期策略:设置合理的TTL,自动清理冷门内容点赞数据
避坑指南 ⚠️
- 防刷机制:结合IP限制和用户行为分析,防止机器人刷赞
- 数据一致性:定期校验Redis与数据库数据,建立补偿机制
- 容量监控:设置内存报警,防止Redis内存爆满
- 集群模式:生产环境建议使用哨兵或集群模式保证高可用
Redis就像点赞系统的"超级充电宝"🔋,让海量点赞数据的处理变得轻松愉快,通过合理的数据结构选择和架构设计,你的点赞系统可以轻松应对百万级并发,为用户提供丝滑流畅的互动体验。

下次当你给喜欢的视频点赞时,不妨想想背后这位默默工作的"Redis小助手"🤖,正是它让你的每一次喜欢都能被瞬间记录和传递!
(本文技术方案基于2025年主流实践,具体实现请根据实际业务需求调整)
本文由 禾俊捷 于2025-07-31发表在【云服务器提供商】,文中图片由(禾俊捷)上传,本平台仅提供信息存储服务;作者观点、意见不代表本站立场,如有侵权,请联系我们删除;若有图片侵权,请您准备原始证明材料和公证书后联系我方删除!
本文链接:https://vps.7tqx.com/wenda/498506.html
最新文章
-

通信创新📠传真技术的革新与应用:数字化转型驱动通信新变革
2025-08-05 -

🔥游戏攻略🔥全新赛季🔥三国:谋定天下S5赛季超全新策略玩法揭秘
2025-08-05 -
香港VPS 高速网络 预算有限?onetechcloud高速VPS,22元畅享香港CN2专线
2025-08-05 -
开发工具 数据管理 Codelite助力数据库操作便捷实现,轻松扩展你的开发能力
2025-08-05 -

职业攻略 热门推荐 详解 秦时明月世界平民职业全指南
2025-08-05 -
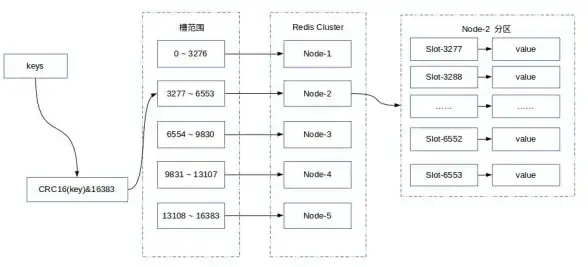
Redis运维 性能提升 Redis缩容与扩容,优化资源配置,助力系统性能提升
2025-08-05 -

全流程 私服搭建秘籍|深度解析】云服务器多类型部署指南—云计算实用手册
2025-08-05 -
存储优化 磁盘分区详解:助力系统高效运行的核心策略
2025-08-05

发表评论