
上一篇
扩容准备 系统优化:服务器、存储器与数据库扩容前的关键准备事项
扩容准备 | 系统优化:服务器、存储器与数据库扩容前的关键准备事项
场景引入:当系统开始"喘不过气"
想象一下,你的电商平台正在经历一场突如其来的流量风暴——也许是某个爆款商品突然被网红带货,也许是年度大促提前引爆,后台监控面板上的曲线像坐了火箭一样往上窜,服务器负载飙红,数据库查询速度肉眼可见地变慢,甚至偶尔弹出几个"504 Gateway Time-out"的错误页面,技术团队的电话开始响个不停,而老板在群里发了个"?"......

这时候你才意识到:扩容不能再拖了,但盲目加机器就像给高烧病人直接塞冰块——可能适得其反,以下是我们在2025年技术实践中总结的扩容前必须完成的"体检清单"。
服务器扩容:不只是加机器那么简单
先给系统做"CT扫描"
- 负载分析:用
top/htop看CPU瓶颈,用vmstat查内存压力,iotop揪出磁盘I/O大户 - 黄金指标:CPU利用率超过70%持续15分钟?内存swap频繁触发?这些才是真扩容信号
- 冷知识:2025年某云厂商统计显示,30%的扩容需求其实通过优化线程池配置就能解决
选择最优扩容策略
- 垂直扩容(升级配置):适合有单点性能瓶颈的数据库主节点
- 水平扩容(增加实例):微服务架构的首选,但要注意会话保持问题
- 混合方案:比如把MySQL从16核128G升级到32核256G(垂直),同时增加5个应用节点(水平)
躲开这些坑
- 资源争抢:新老实例抢同一个共享存储?提前规划存储挂载点
- 配置漂移:用Ansible/SaltStack确保新增节点的系统参数与现有集群一致
- 许可证陷阱:某些商业软件按核心数收费,扩容可能触发天价账单
存储扩容:别等磁盘写满才行动
容量规划的三重境界
- 青铜:看当前剩余空间
- 白银:结合业务增长曲线预测(比如订单量每月增长23%)
- 王者:建立"容量水位线"模型,包括:
- 安全水位(剩余30%)
- 预警水位(剩余15%)
- 熔断水位(剩余5%时自动停止非核心业务写入)
性能瓶颈侦查
- SSD寿命检查:
smartctl查看剩余PE次数,企业级SSD在2025年普遍支持每天1次全盘写入 - RAID重组:扩容RAID5/6阵列时,大容量磁盘重构可能耗时数天,建议选择业务低谷期
- 冷热数据分离:把访问频率低于1次/周的日志数据自动归档到对象存储
最容易被忽视的细节
- inode用尽:即使磁盘空间充足,小文件太多可能先耗尽inode
- LVM陷阱:扩展逻辑卷后别忘了
resize2fs,某公司曾因此白白浪费10TB空间 - 快照依赖:存储快照会占用原卷性能,大促前记得清理陈旧快照
数据库扩容:最危险的"外科手术"
选择你的"手术方案"
| 方案 | 适用场景 | 停机时间 | 风险等级 |
|---|---|---|---|
| 主从切换 | 读压力大,写QPS低 | 分钟级 | |
| 分库分表 | 单表超过5000万行 | 小时级 | |
| 分布式数据库迁移 | 业务需要跨地域扩展 | 天级 | |
| 云数据库弹性扩展 | 云环境,支持在线扩容 | 近乎零 |
术前必备检查项
- 索引健康度:膨胀率超过30%的索引需要重建
- 长事务排查:运行超过1小时的事务可能导致扩容阻塞
- 连接池配置:突然增加的节点可能耗尽数据库连接数
真实案例教训
- 字段类型坑:某金融系统扩容后发现时间戳字段用
INT存储,2038年问题提前爆发 - 字符集惨案:从MySQL 5.7升级到8.0时,
utf8mb3和utf8mb4混用导致数据截断 - 隐式锁灾难:没有检查
innodb_deadlock_detect参数导致分布式死锁
终极 checklist:扩容前5小时该做什么
- 数据备份:至少保留两份不同介质的全量备份
- 回滚方案:详细记录每个步骤,确保10分钟内能退回原状态
- 监控增强:临时增加关键指标的采集频率(如从1分钟调整为15秒)
- 沟通矩阵:明确通知市场/客服等部门具体维护时间窗口
- 压力测试:用历史流量2倍的模拟请求验证新架构
扩容是门艺术
2025年的技术实践告诉我们:最成功的扩容往往悄无声息——用户根本没察觉到系统曾经历"心脏搭桥手术",当服务器报警声响起时,最好的急救措施其实是日常定期进行的"健康体检",下次我们会聊聊《扩容后的48小时:如何避免胜利后的崩溃》,敬请期待。

(本文技术要点参考2025年8月全球架构师峰会案例库及多家云厂商技术白皮书)
本文由 冉皓 于2025-08-01发表在【云服务器提供商】,文中图片由(冉皓)上传,本平台仅提供信息存储服务;作者观点、意见不代表本站立场,如有侵权,请联系我们删除;若有图片侵权,请您准备原始证明材料和公证书后联系我方删除!
本文链接:https://vps.7tqx.com/wenda/503003.html
最新文章
-

热门攻略 新手指南 极速入门 剑中》新手必读全攻略,轻松快速上手秘籍!
2025-08-05 -
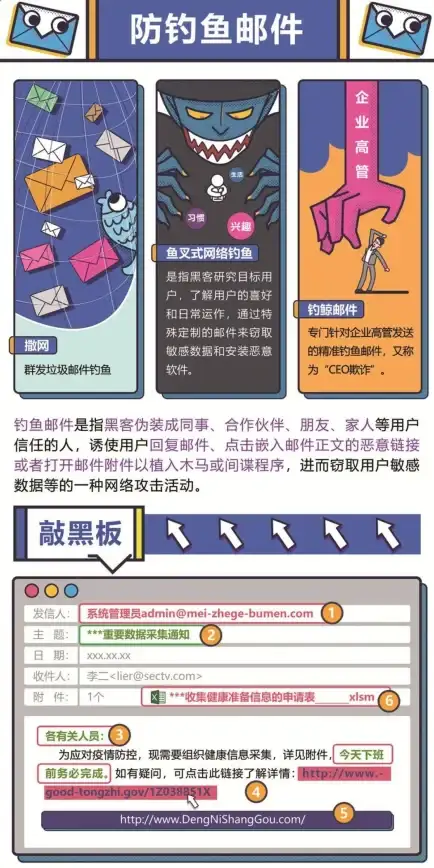
动作游戏🔥技能攻略🔥高手必读 真三国无双起源灭尽刚牙断武艺全面解析
2025-08-05 -
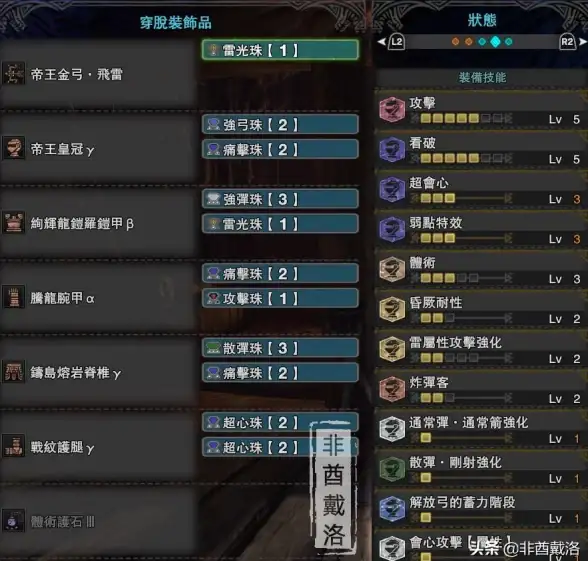
雷弓攻略🔥技巧实用 怪物猎人雷弓怎么玩才强?
2025-08-05 -
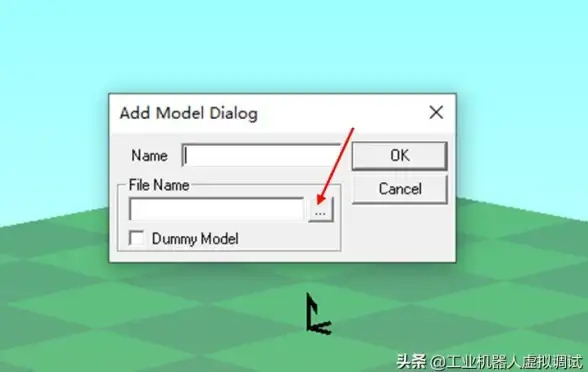
CAD教程🚀dxf文件打开方法,详细步骤教你轻松搞定
2025-08-05 -
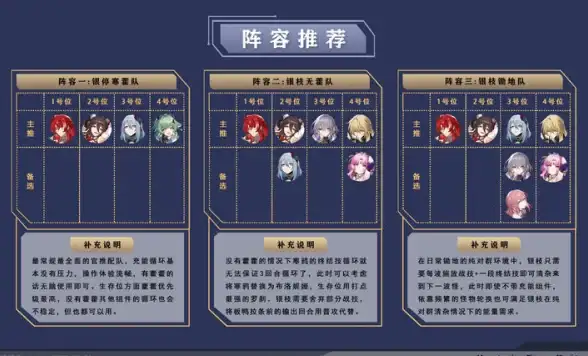
移动建站必看|ZBlog移动端Logo自适应方法锦集!实用教程】
2025-08-05 -

Hive GBK编码:Hive加载GBK编码数据库的方法与步骤
2025-08-05 -
🔥攻略秘籍🔥提升必看🔥航海王壮志雄心岛屿激斗快速升级与资源获取全解析
2025-08-05 -

搜索技巧✨win7系统内置搜索功能新手入门教程
2025-08-05

发表评论