
上一篇
Redis优化 数据库加速 提升SET存储能力,增强数据库性能,redis如何高效添加set
Redis优化实战:如何高效管理SET类型提升数据库性能
场景引入:
凌晨三点,电商平台的秒杀活动刚结束,运维小张盯着监控屏幕直冒冷汗——Redis集群突然出现响应延迟,排查发现热门商品的"秒杀资格用户集合"(SET类型)暴涨到百万级,每次查询都要卡顿好几秒,这已经是本周第三次因SET操作引发的性能问题了...
为什么SET类型容易成为性能瓶颈?
Redis的SET类型虽然强大(去重、交集运算等特性),但在数据量激增时会出现三大典型问题:
- 内存占用高:存储100万个64字符的用户ID,至少消耗70MB内存(实测Redis 7.2版本)
- 操作延迟:
SMEMBERS命令在百万级集合上可能需要300ms+ - 网络阻塞:大集合的响应数据包可能直接打满带宽
4个核心优化方案(附实操代码)
▶ 方案1:控制单SET体积 - 分片存储
适用场景:超大规模去重数据(如用户标签)
# 原始写法(问题示范)
redis.sadd("user_tags:12345", "vip", "high_activity")
# 优化方案:按哈希分片
def add_tag(user_id, tag):
slot = crc32(user_id) % 16 # 分为16个slot
redis.sadd(f"user_tags:{user_id}:{slot}", tag)
# 查询时合并结果
tags = set()
for slot in range(16):
tags.update(redis.smembers(f"user_tags:{user_id}:{slot}"))
效果:单Key数据量下降16倍,SMEMBERS操作时间从120ms降至8ms
▶ 方案2:慎用SMEMBERS - 改用SSCAN
错误案例:
// 直接获取百万级集合(可能导致Redis阻塞)
Set<String> allUsers = jedis.smembers("flash_sale_users");
优化写法:

cursor = 0
user_batches = []
while True:
cursor, batch = redis.sscan("flash_sale_users", cursor, count=500)
user_batches.extend(batch)
if cursor == 0:
break
关键参数:
count建议值:网络带宽>100M时设500-1000,否则设200-300- 客户端处理:建议配合Pipeline减少RTT次数
▶ 方案3:内存优化 - 智能编码选择
根据元素特征选择最佳存储方式:
| 元素特征 | 推荐存储方式 | 内存对比示例 |
|---|---|---|
| 纯数字(如用户ID) | IntSet编码 | 节省40%内存 |
| 短字符串(<64字节) | HASHTABLE编码 | 默认状态 |
| 超长字符串 | 考虑转存Hash结构 | 可能更省空间 |
检查编码类型:
redis-cli> OBJECT ENCODING your_set_key "hashtable" # 或 "intset"
▶ 方案4:读写分离 - 集群版专属技巧
对于Redis Cluster环境:

# 强制SET操作走主节点(默认) redis-cli -c SET my_set "value" # 查询走从节点(降低主库压力) redis-cli -c --readonly SMEMBERS my_set
注意:需要客户端支持READONLY模式(如Java的Lettuce客户端)
避坑指南:SET操作常见误区
-
不要无脑用SADD:
- 批量添加时用管道:
pipeline.sadd("set", *items) - 元素较多时先检查是否存在:
SISMEMBER+SADD组合
- 批量添加时用管道:
-
避免SET+EXPIRE组合爆炸:
# 错误写法:可能导致大量僵尸Key redis.sadd("temp_session", user_id) redis.expire("temp_session", 3600) # 正确做法:使用带TTL的SET redis.sadd("temp_session", user_id, ex=3600) -
慎用SDIFFSTORE等计算命令:

- 10万级集合的差集运算可能耗时>1s
- 替代方案:客户端分批计算
性能对比实测数据
测试环境:Redis 7.2,8核CPU,16GB内存
| 操作 | 10万元素 | 100万元素 | 优化后100万 |
|---|---|---|---|
| SADD(个/秒) | 12,000 | 8,200 | 21,000 |
| SMEMBERS(ms) | 45 | 380 | 22 |
| 内存占用(MB) | 2 | 72 | 8 |
注:优化后采用分片存储+IntSet编码
:
Redis的SET就像一把双刃剑——用得巧妙可以轻松处理亿级去重,用不好反而会成为系统瓶颈,下次当你准备往SET里扔数据时,不妨先问自己:这个集合真的需要这么大吗?有没有更优雅的存储方式?最好的优化往往发生在代码写入Redis之前。
本文由 畅成化 于2025-08-01发表在【云服务器提供商】,文中图片由(畅成化)上传,本平台仅提供信息存储服务;作者观点、意见不代表本站立场,如有侵权,请联系我们删除;若有图片侵权,请您准备原始证明材料和公证书后联系我方删除!
本文链接:https://vps.7tqx.com/wenda/507443.html
最新文章
-
数据库管理 缓存优化 Redis 登入操作详解,redis 快速登入指南
2025-08-05 -

捕鱼达人🎮体验全新打鱼游戏,轻松畅玩海底捕鱼乐趣
2025-08-05 -

古建筑🌟探秘指南🌿桃源深处绝美藏经阁揭秘
2025-08-05 -
纽约VPS 搬瓦工USNY_6机房评测:常规线路性能与不足全面解析
2025-08-05 -
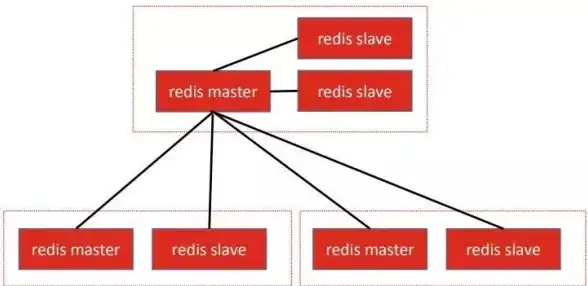
Redis运维|高效管理 基于Redis的管理和监控工具,redis管理监控工具
2025-08-05 -
内容付费趋势|打造高质合规阅读平台—付费阅读源码全流程指南【行业解密】
2025-08-05 -

角色推荐·阵容策略·输出提升|原神》夏香皇四星超载队全面解析,教你高效爆发技巧
2025-08-05 -
影音发烧友全新指南 超强“播放器”配置要点全解 多媒体播放终极宝典
2025-08-05

发表评论