
上一篇
文件处理|数据提取 C语言技巧:从txt文件中读取特定数据库信息,c 读取txt文件某一个数据库
用C语言精准提取txt文件中的数据库信息
场景引入:当数据藏在文本海洋中
想象一下这个场景:你接手了一个老项目,发现关键数据都存储在一个巨大的txt文件里,格式杂乱无章,你需要从中提取出特定数据库的记录,比如所有用户ID为1001到1050的信息,手动筛选?那太费时了!用Excel处理?文件太大打不开!这时候,C语言的文件处理能力就能大显身手了。
基础准备:理解文本文件的结构
我们需要明确txt文件中数据的组织方式,假设我们的数据文件database.txt内容如下:
[User]
ID:1001 Name:张三 Age:25 Dept:市场部
ID:1002 Name:李四 Age:30 Dept:技术部
ID:1003 Name:王五 Age:28 Dept:人事部
[Order]
OrderID:2001 UserID:1001 Amount:1500.00
OrderID:2002 UserID:1002 Amount:2300.50这种结构虽然人类可读,但对程序来说需要特定解析逻辑,我们的目标是提取[User]段中ID在1001-1050之间的记录。
完整代码实现
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAX_LINE_LENGTH 256
int main() {
FILE *file = fopen("database.txt", "r");
if (file == NULL) {
printf("无法打开文件!\n");
return 1;
}
char line[MAX_LINE_LENGTH];
int inUserSection = 0; // 标记是否在[User]段
printf("提取到的用户信息:\n");
while (fgets(line, sizeof(line), file)) {
// 去除行尾的换行符
line[strcspn(line, "\n")] = '\0';
// 检查是否进入[User]段
if (strcmp(line, "[User]") == 0) {
inUserSection = 1;
continue;
}
// 检查是否离开[User]段
if (line[0] == '[' && strcmp(line, "[User]") != 0) {
inUserSection = 0;
continue;
}
// 如果在User段,处理用户数据
if (inUserSection) {
int id;
char name[50], dept[50];
int age;
// 使用sscanf解析行数据
if (sscanf(line, "ID:%d Name:%s Age:%d Dept:%s", &id, name, &age, dept) == 4) {
// 检查ID是否在目标范围内
if (id >= 1001 && id <= 1050) {
printf("ID: %d, 姓名: %s, 年龄: %d, 部门: %s\n", id, name, age, dept);
}
}
}
}
fclose(file);
return 0;
}
代码解析:关键技巧点
文件打开与基础检查
FILE *file = fopen("database.txt", "r");
if (file == NULL) {
printf("无法打开文件!\n");
return 1;
}
这是C语言文件操作的标准开头,fopen函数以只读模式("r")打开文件,并检查是否成功。
逐行读取技巧
while (fgets(line, sizeof(line), file)) {
line[strcspn(line, "\n")] = '\0';
// ...处理逻辑...
}
fgets是安全读取行的最佳选择,它会自动处理缓冲区大小。strcspn配合字符串操作去除换行符是常见技巧。

段标记处理
if (strcmp(line, "[User]") == 0) {
inUserSection = 1;
continue;
}
通过设置inUserSection标志变量,我们可以精确控制只处理目标段落的逻辑。
数据解析与条件筛选
if (sscanf(line, "ID:%d Name:%s Age:%d Dept:%s", &id, name, &age, dept) == 4) {
if (id >= 1001 && id <= 1050) {
// 输出符合条件的记录
}
}
sscanf是C语言中强大的字符串解析函数,返回值表示成功匹配的参数数量,这里我们检查是否4个字段都解析成功。
进阶技巧:处理更复杂的情况
情况1:字段顺序不固定
如果数据行的字段顺序可能变化,比如有时是"Name:张三 ID:1001",我们可以调整解析策略:
char *token = strtok(line, " ");
while (token != NULL) {
if (strncmp(token, "ID:", 3) == 0) {
id = atoi(token + 3);
}
else if (strncmp(token, "Name:", 5) == 0) {
strcpy(name, token + 5);
}
// 类似处理其他字段...
token = strtok(NULL, " ");
}
情况2:处理带空格的值
如果姓名可能包含空格(如"张三 三"),我们需要更精细的解析:
char *idPos = strstr(line, "ID:");
char *namePos = strstr(line, "Name:");
char *agePos = strstr(line, "Age:");
char *deptPos = strstr(line, "Dept:");
if (idPos && namePos && agePos && deptPos) {
sscanf(idPos + 3, "%d", &id);
// 提取Name到Age之间的部分
*agePos = '\0'; // 临时终止字符串
strcpy(name, namePos + 5);
*agePos = 'A'; // 恢复原字符
sscanf(agePos + 4, "%d", &age);
strcpy(dept, deptPos + 5);
}
性能优化技巧
处理大文件时,效率很重要:
-
缓冲区设置:可以使用
setvbuf设置更大的缓冲区
char buffer[1024 * 1024]; // 1MB缓冲区 setvbuf(file, buffer, _IOFBF, sizeof(buffer));
-
批量处理:积累一定数量的记录再统一处理,减少I/O操作
-
内存映射:对于超大文件,考虑使用内存映射文件技术
错误处理与健壮性
完善的程序需要考虑各种异常情况:
// 在sscanf后添加错误检查
if (sscanf(...) != 4) {
fprintf(stderr, "警告:行格式不正确: %s\n", line);
continue;
}
// 检查字段有效性
if (age < 18 || age > 100) {
fprintf(stderr, "警告:异常年龄值: %d\n", age);
}
通过这个实例,我们学习了如何用C语言从txt文件中提取特定数据库信息,关键点包括:
- 使用
fgets安全读取行 - 用标志变量跟踪当前解析状态
- 灵活运用
sscanf或strtok解析结构化文本 - 添加适当的错误处理和边界检查
掌握了这些技巧,你就能轻松处理各种文本数据提取任务,再也不用面对杂乱的数据文件发愁了!
本文由 喻芳懿 于2025-08-02发表在【云服务器提供商】,文中图片由(喻芳懿)上传,本平台仅提供信息存储服务;作者观点、意见不代表本站立场,如有侵权,请联系我们删除;若有图片侵权,请您准备原始证明材料和公证书后联系我方删除!
本文链接:https://vps.7tqx.com/wenda/512181.html
最新文章
-

摩尔庄园手游鸭蛋收集技巧详解
2025-08-05 -

CG动画人必看|限时指南!Softimage软件下载安装实用攻略 软件资源教程
2025-08-05 -

策略🔥高效🔥团队 合理搭配丨《新月同行》最强支援角色与配合技巧揭秘
2025-08-05 -
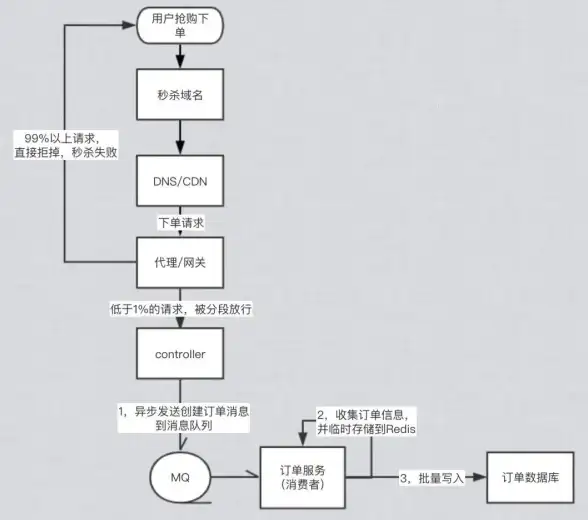
消息队列 应用拓展 Redis为消息队列注入新活力,redis配置实现多样化消息队列
2025-08-05 -
办公神器✨效率提升|小鱼教您保存快捷键,快速提升办公效率的实用技巧
2025-08-05 -

系统优化 XP系统极速下载,安全无忧助力高效操作体验
2025-08-05 -

🔥攻略•技巧•实战丨战争雷霆M247近炸引信弹链安装全解析与实用心得分享
2025-08-05 -
热门推荐🔥dnf起源魔枪哪个职业最强解析!职业选择指南
2025-08-05

发表评论