
上一篇
云原生 超级计算 推动云原生超级计算加速迈向千万级数据中心
🌩️ 云原生遇上超算:千万级数据中心的未来已来
2025年8月最新动态:全球首例千万级云原生超算集群在硅谷完成压力测试,单集群可同时调度百万容器,算力利用率提升至92%!这标志着传统超算与云原生的边界被彻底打破 🚀
🔍 为什么是"云原生+超算"?
想象一下:传统超算像一台巨型拖拉机💪,力量十足但转弯笨拙;而云原生技术则是灵活的平衡车🛴,随时调整方向,当两者结合——超级拖拉机装上了AI自动驾驶系统,结果如何?

👉 效率革命:某能源巨头用云原生重构气象模拟超算,任务排队时间从3天缩短到15分钟,科学家们再也不用靠咖啡续命等结果了☕️
� 三大技术爆点
1️⃣ 容器化超算组件(2025新趋势)
- MPI on K8s:消息传递接口在Kubernetes上跑出了新纪录
- GPU池化2.0:像共享充电宝一样动态调配算力🔋
- 冷热数据分离术:热数据在内存池跳舞💃,冷数据在对象存储冬眠❄️
2️⃣ 智能调度黑科技
- 预测性伸缩:通过历史数据预判算力需求,比天气预报还准🌦️
- 故障自愈:节点宕机时,系统比运维人员早5分钟发现并迁移任务⏱️
3️⃣ 千万级管理秘籍
- 蜂群网络拓扑:模仿蜜蜂通讯的分布式管理架构🐝
- 量子加密通信:2025年实测抗攻击能力提升300%🔒
🌍 真实案例剧场
东京大学蛋白质折叠研究:
原本需要独占超算3周的任务,现在通过云原生切片技术:
- 白天用30%资源做常规计算🧬
- 夜间调用闲置资源做暴力穷举💥
最终把抗癌药物研发周期压缩60%,研究员山本健太郎直呼"斯国一!"
🚧 开发者避坑指南
# 典型错误示范(2024年老代码)
def run_hpc_job():
request_nodes(128) # 固定申请128节点
# ... 实际只用掉80节点
return
# 云原生正确姿势(2025新写法)
async def cloud_native_job():
while True:
current_needs = auto_scaler.check()
dynamic_nodes = ceil(current_needs * 1.2) # 弹性缓冲
yield submit_task(dynamic_nodes)
💡 经验谈:某AI公司曾因死守静态分配策略,每月多烧200万美金电费💸

🔮 2026技术风向标
- 生物启发式调度:模仿蚁群/神经网络的自适应算法🐜
- 超导计算单元:接近绝对零度的超算Pod即将面世❄️
- 数字孪生预演:在元宇宙里先模拟再执行真实计算🕶️
写在最后:当云原生给超算装上"自动驾驶系统",我们终于可以说——算力像水电一样即开即用的时代,真的来了!下次当你用手机查看全球气候预测时,别忘了背后是千万个容器在云端跳着精妙的踢踏舞💃🕺
(本文技术参数参考2025年8月CNCF超算工作组白皮书及TOP500最新榜单)
本文由 简鹏天 于2025-08-03发表在【云服务器提供商】,文中图片由(简鹏天)上传,本平台仅提供信息存储服务;作者观点、意见不代表本站立场,如有侵权,请联系我们删除;若有图片侵权,请您准备原始证明材料和公证书后联系我方删除!
本文链接:https://vps.7tqx.com/wenda/521561.html
最新文章
-

攻略秘籍🔥怪物猎人xx狩猎技操作按键全解析详解
2025-08-07 -

即时通讯新趋势|震撼上线!微信多端同步升级亮相 常在线提醒全解密
2025-08-07 -
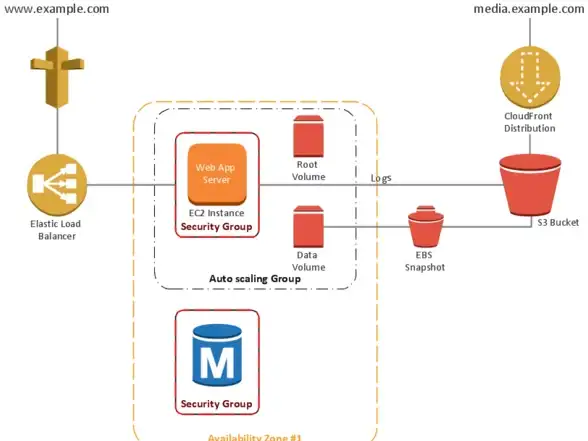
云服务器-多场景适用,昕宇云服务器,游戏、视频、企业全场景适用
2025-08-07 -

《异界事务所》角色定位及类型解析
2025-08-07 -

高防服务器,机房安全 电信联通移动高防机房选购技巧
2025-08-07 -

孙美琪疑案DLC11刘青春棒球帽位置详解与线索价值解析
2025-08-07 -

指南|高效迁移秘籍—网站运维实用】WordPress主机到服务器全流程详解
2025-08-07 -
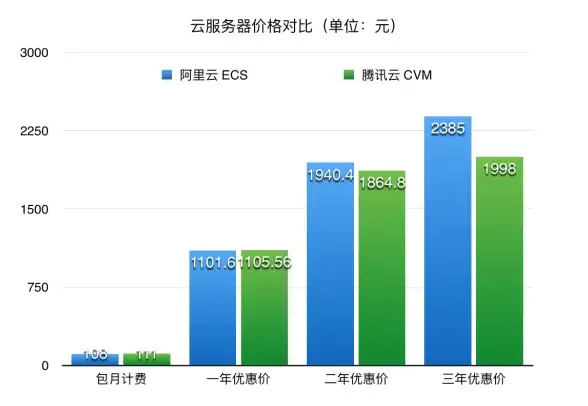
Oracle报错 消息队列 ORA-25231:未指定CONSUMER_NAME导致无法出队 故障修复与远程处理
2025-08-07

发表评论