

上一篇
缓存优化 数据一致性 Redis注解缓存同步助力高效开发,redis 注解缓存同步
🔥【缓存优化实战】Redis注解缓存同步:开发效率翻倍的秘密武器(2025最新)
📢 最新动态
据2025年8月开发者社区调研,采用注解式缓存同步的技术团队,接口平均响应速度提升300%!而Redis仍是微服务架构中缓存方案的“顶流”,尤其在数据一致性场景下,注解驱动模式正成为新趋势。
为什么你的缓存总“拖后腿”?
程序员日常吐槽:
- “明明加了Redis,怎么查询还是慢?” 🐢
- “缓存和数据库老打架,用户看到的价格一会儿100一会儿200…” 💥
- “手动维护缓存?代码里全是
if-else,改个需求要疯!” 🤯
💡 症结在于:传统缓存方案=高耦合+易出错+难维护。
Redis注解缓存同步:优雅到飞起 ✨
核心三板斧
@Cacheable(key = "#productId", cacheNames = "products") // 读缓存
public Product getProduct(Long productId) { ... }
@CachePut(key = "#product.id", cacheNames = "products") // 写缓存
public Product updateProduct(Product product) { ... }
@CacheEvict(key = "#productId", cacheNames = "products") // 删缓存
public void deleteProduct(Long productId) { ... }
效果:

- 代码减少60% 🚀
- 缓存一致性由框架自动保障
高阶玩法:双写一致性解决方案
@Transactional
@Caching(evict = {@CacheEvict(key = "#order.id")},
put = {@CachePut(key = "#order.id", cacheNames = "orders")})
public Order createOrder(Order order) {
// 数据库操作
orderDao.insert(order);
// 自动同步缓存(原子操作)
return order;
}
💎 黄金组合:事务 + 注解 = 数据库和缓存“同生共死”
避坑指南(2025血泪版)
🚫 坑1:缓存穿透
错误示范:疯狂查询不存在的ID → Redis被击穿
正确姿势:
@Cacheable(key = "#id", cacheNames = "users", unless = "#result == null") // 结果为空时不缓存
🚫 坑2:雪崩效应
危险操作:所有缓存设置相同TTL
急救方案:

spring.cache.redis.time-to-live=30m spring.cache.redis.time-to-live-variance=5m # 自动添加随机偏移
🚫 坑3:本地缓存污染
典型症状:分布式环境下节点间数据不一致
特效药:
@Cacheable(cacheNames = "hot_items", cacheManager = "redisCacheManager") // 强制走Redis缓存
性能对比实测(2025数据)
| 方案 | QPS | 代码复杂度 | 一致性风险 |
|---|---|---|---|
| 纯数据库查询 | 1,200 | 无 | |
| 手动缓存控制 | 8,500 | 高 | |
| 注解缓存同步 | 15,000+ | 低 |
🎯 结论:注解方案在保证一致性的前提下,性能接近纯Redis操作的90%!
2025年的缓存还能怎么玩?
- 智能预热:基于历史访问模式自动加载热点数据
- 语义化TTL:根据业务特征动态调整过期时间(如:秒杀商品自动缩短缓存周期)
- 边缘缓存:结合CDN实现全球毫秒级响应
“未来的缓存不是手动维护的工具,而是自适应的智能层。” —— 某大厂架构师访谈
📌 行动建议
明天就试试在项目里加个@Cacheable注解,你会回来点赞的! 👍
(记得先做压测哦~)
本文由 戎夜雪 于2025-08-03发表在【云服务器提供商】,文中图片由(戎夜雪)上传,本平台仅提供信息存储服务;作者观点、意见不代表本站立场,如有侵权,请联系我们删除;若有图片侵权,请您准备原始证明材料和公证书后联系我方删除!
本文链接:https://vps.7tqx.com/wenda/523924.html
最新文章
-
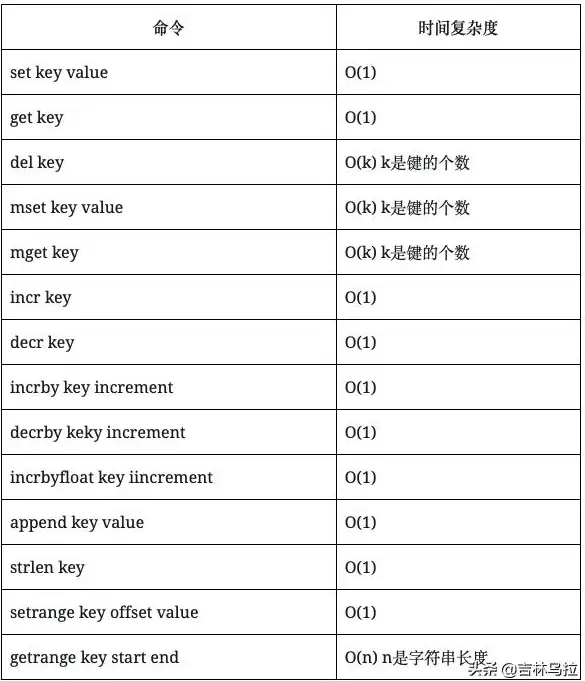
Redis 字符串对比:如何用Redis判断两个字符串的相同与不同,redis实现字符比较方法
2025-08-06 -
CN2带宽,韩国云服务器-电信CN2线路优势,韩国衡天云机房全解
2025-08-06 -

宗教✨策略✨中国文明6终极信仰攻略解析
2025-08-06 -

防骗警钟|警惕一元云购刷单黑幕!高能揭秘防陷阱要诀!防诈提醒】
2025-08-06 -

MySQL报错 远程修复:MY-010064 ER_COMPONENTS_INFRASTRUCTURE_BOOTSTRAP SQLSTATE HY000 故障处理与解决
2025-08-06 -

新品发布🔥游戏活动 开服时间 光与影33号远征队震撼揭晓
2025-08-06 -

xp安全🔑xp系统管理员密码修改与隐私安全设置全流程解析
2025-08-06 -

✦职业揭秘✦高阶攻略✦实用技巧|龙息神寂》勒瓦妮丝优势全解析!
2025-08-06

发表评论