
上一篇
Redis优化|内存管理 通过压缩数组技术释放内存空间,Redis的压缩数组原理解析
🔍 Redis内存优化秘籍:压缩数组技术原理解析
场景引入:
凌晨3点,你的手机突然狂震——线上Redis内存爆了!📱💥 监控显示一个Key存储了10万个用户ID,占用了500MB内存,这时候你突然想起同事提过的「压缩数组」,但它是怎么省内存的?今天我们就拆解这个Redis的"瘦身魔法"!
为什么需要压缩数组?
Redis的ziplist(压缩列表)是为小数据量设计的紧凑型结构,相比常规的哈希表能节省30%~70%内存,比如存储[1,2,3]:
- 普通链表:每个节点含前后指针(各8字节)+ 数据 → 至少48字节
- 压缩列表:连续内存存储 → 仅需12字节 🎉
适用场景:
✅ 小型列表/哈希/有序集合(元素数量<512且值<64字节,默认配置)
✅ 需要频繁修改但数据量不大的场景
压缩数组的底层黑科技
内存布局解剖 🧠
一个ziplist由三部分组成:
[总字节数][尾节点偏移量][节点1][节点2]...[结束标记] 每个节点采用变长编码:

[前驱节点长度][当前节点编码][数据内容] 精妙设计:
- 长度字段自适应:用1或5字节存储长度(类似UTF-8设计)
- 数据紧挨着存:消除指针开销(对比Java的ArrayList)
实战效果对比
存储100万个数字(1~100):
| 结构 | 内存占用 | 特点 |
|---|---|---|
| 普通链表 | ~48MB | 读写O(1)但内存浪费 |
| 压缩列表 | ~12MB | 读写O(n)但省内存 |
💡 提示:可通过
redis.conf调整hash-max-ziplist-entries等参数控制转换阈值
什么情况下会"翻车"?
性能陷阱 ⚠️
由于是连续内存,大ziplist的插入/删除会导致内存拷贝:
# 在1000个元素的ziplist头部插入数据 # 需要移动所有后续节点!
典型误用案例
- 错误:把10万用户ID塞进一个ziplist
- 正确:拆分成多个
key:user_ids:[分段号]
高级技巧:让压缩更极致
强制使用ziplist
对已有大数据可用DEBUG RELOAD触发转换(谨慎操作!):

CONFIG SET hash-max-ziplist-entries 1024
数据压缩二重奏
结合LZF压缩算法(需插件):
原始数据 → ziplist → LZF压缩 → 存储 2025年新动向 🌟
根据Redis Labs 2025-08披露,未来版本将:
- 支持
ziplist的部分惰性解压 - 增加
float类型的特殊编码(节省浮点数存储)
:
压缩数组像Redis的"真空压缩袋"🧳,用CPU换内存,记住它的黄金法则:小而美的数据才能发挥最大威力!下次遇到内存报警,不妨先查查是否误用了这个神器~
🛠️ 检查你的Redis:执行
MEMORY USAGE key_name看看哪些Key值得优化吧!
本文由 锐赞怡 于2025-08-03发表在【云服务器提供商】,文中图片由(锐赞怡)上传,本平台仅提供信息存储服务;作者观点、意见不代表本站立场,如有侵权,请联系我们删除;若有图片侵权,请您准备原始证明材料和公证书后联系我方删除!
本文链接:https://vps.7tqx.com/wenda/529966.html
最新文章
-
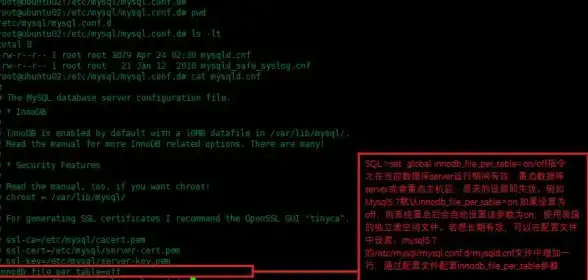
数据库安全 配置优化 MySQL安全配置要点汇总
2025-08-06 -

电脑维护🖥自动重启原因解析及小鱼实用修复技巧
2025-08-06 -

攻略·技巧·详解 无限暖暖》焦虑布袋任务全攻略,轻松通关必看!
2025-08-06 -

MySQL 字符集设置方法详解:Linux系统下的MySQL数据库服务器字符集设置
2025-08-06 -
飞行✈模拟✈竞技 2025最强热门开飞机手游排行榜大揭秘
2025-08-06 -

爆炸特效🎬电影揭秘|电影级爆炸场景制作全攻略,轻松掌握震撼视觉效果
2025-08-06 -
聚焦|GoodReader安全指南全解析|教育科技风险预警】下载合规必读,实用技巧速览
2025-08-06 -

云安全-合规认证 黑龙江棉花云服务器安全合规与认证
2025-08-06

发表评论