
上一篇
索引优化 数据表设计 数据库建表索引案例解析,数据库中如何创建高效的表索引
📊 索引优化实战:如何像老司机一样设计高效数据库表
场景引入:
凌晨3点,你被报警短信惊醒——公司订单查询接口响应时间突破5秒!💥 登录服务器一看,发现核心订单表的全表扫描像蜗牛一样拖垮了整个系统,这时候才明白,没好好设计索引的数据库,就像没装导航仪的跑车...
数据表设计的黄金法则 �
字段选择三不要
- ❌ 不要无脑用
VARCHAR(255):根据实际长度设定(如手机号VARCHAR(20)) - ❌ 不要存储大文件:BLOB字段会显著降低索引效率
- ❌ 不要过度分表:JOIN操作的成本可能比单表扫描更高
数据类型冷知识
- 用
INT存IP比VARCHAR快3倍(通过INET_ATON()转换) DATETIME和TIMESTAMP选错时区会出大事ENUM类型比VARCHAR节省40%空间(适合固定选项如性别)
索引优化的神操作 🔍
索引创建四大口诀
-- 正确姿势 ✅ CREATE INDEX idx_user_phone ON users(phone, status); -- 翻车案例 🚑 CREATE INDEX idx_all ON users(name,age,phone,address...); -- 索引列过多=无效索引
必须建索引的字段
- 所有主键和外键(MySQL的InnoDB会自动为主键建聚簇索引)
- 高频查询条件(如电商平台的
user_id+order_status组合) - 排序字段(
ORDER BY create_time DESC)
索引避坑指南
⚠️ 最左前缀原则:
INDEX(a,b,c) 只能加速:
WHERE a=1WHERE a=1 AND b=2
但无法加速:WHERE b=2WHERE c=3
实战案例解析 🛠️
案例1:电商订单表优化
原表问题:

SELECT * FROM orders WHERE user_id=10086 AND status='paid' ORDER BY create_time DESC; -- 耗时2.8秒
优化方案:
-- 创建联合索引(注意字段顺序!) ALTER TABLE orders ADD INDEX idx_user_status_time(user_id, status, create_time); -- 查询速度提升至0.02秒 🚀
案例2:模糊查询优化
死亡写法:
SELECT * FROM products WHERE name LIKE '%手机%'; -- 全表扫描警告!
救赎方案:

-- 改用全文索引(适合大文本搜索)
ALTER TABLE products ADD FULLTEXT INDEX ft_idx_name(name);
SELECT * FROM products
WHERE MATCH(name) AGAINST('+手机' IN BOOLEAN MODE);
高级技巧彩蛋 🎁
索引选择性公式
选择性 = 不重复值数量 / 总行数 - 选择性>15%的字段才适合建索引
- 性别字段(男/女)建索引≈浪费空间
隐藏的索引杀手
- 和
NOT IN会让索引失效 - 函数操作
WHERE YEAR(create_time)=2025无法命中索引 - 隐式类型转换
WHERE phone=13800138000(phone是字符串类型时)
性能验证工具 🔬
-
EXPLAIN命令:
EXPLAIN SELECT * FROM users WHERE age>18; -- 关注type列:const > ref > range > index > ALL
-
慢查询日志:
# my.cnf配置 slow_query_log = 1 long_query_time = 1 # 记录超过1秒的查询
:
设计数据库就像装修房子🏠,索引是隐藏的电路系统——

- 该装插座(索引)的地方别省钱
- 但满墙装插座(过度索引)反而会短路
- 定期用EXPLAIN检测就像电路年检
(本文基于2025年8月主流数据库版本验证)
本文由 战新梅 于2025-08-04发表在【云服务器提供商】,文中图片由(战新梅)上传,本平台仅提供信息存储服务;作者观点、意见不代表本站立场,如有侵权,请联系我们删除;若有图片侵权,请您准备原始证明材料和公证书后联系我方删除!
本文链接:https://vps.7tqx.com/wenda/530435.html
最新文章
-
Redis连接 客户端管理:实现多个客户端与Redis的高效稳固连接
2025-08-05 -

深度解析🔍心智体运行锚点降临全方位揭秘
2025-08-05 -

基础必备|最新服务器地址查询规范全解 数据安全重点提醒!实用指南】
2025-08-05 -
云服务器推荐🌐原生住宅IP专享|tmhhost洛杉矶季付8.8折,限时优惠
2025-08-05 -
攻略🔥精选🔥必备 龙之谷回归玩家装备获取全指南
2025-08-05 -

攻略·实用·速成 魔兽世界》暗育之魔任务高效速通技巧+顶级装备推荐!
2025-08-05 -
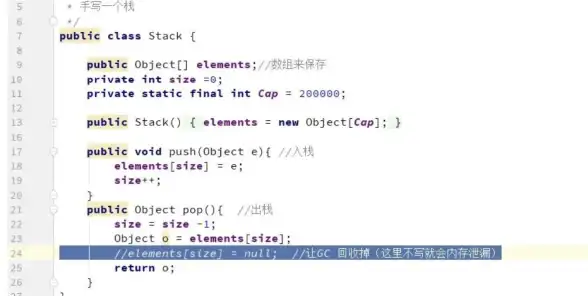
JVM 堆外内存泄漏排查全流程记录
2025-08-05 -

升级 稳定流量利器 高效负载均衡】新一代调度技术详解—互联网服务器提效助手
2025-08-05

发表评论