
上一篇
Redis优化 数据检索 Redis正则表达式助力高效数据匹配与查询
Redis优化 | 数据检索 | Redis正则表达式助力高效数据匹配与查询
2025年8月最新动态:Redis 7.4版本近期发布,进一步优化了正则表达式匹配性能,特别是在大数据集下的查询效率提升了约15%,这一改进让开发者能够更高效地处理复杂的数据检索需求,尤其适用于日志分析、用户行为追踪等场景。
为什么需要Redis正则表达式?
在日常开发中,我们经常遇到需要模糊匹配数据的场景。
- 查找所有以"user:123"开头的键
- 匹配包含特定关键词的日志记录
- 筛选符合某种命名规则的缓存项
这时候,直接使用KEYS命令虽然简单,但在生产环境可能引发性能问题,而Redis的正则表达式功能,配合SCAN等命令,就能既保证查询效率,又避免阻塞风险。
Redis正则表达式基础用法
KEYS命令的基础正则匹配
# 匹配所有以"user:"开头的键 KEYS user:* # 匹配包含"order"的键 KEYS *order* # 匹配以数字结尾的键 KEYS *[0-9]
⚠️ 注意:KEYS会遍历所有键,数据量大时慎用!

更安全的SCAN+正则方案
# 分批次扫描匹配 SCAN 0 MATCH user:* COUNT 100
通过游标分批获取,避免长时间阻塞。
高级匹配技巧
字符集匹配
# 匹配user:后跟1-3位数字的键 KEYS user:[0-9][0-9][0-9] # 匹配包含字母a-f的键 KEYS *[a-f]*
排除特定模式
Redis正则不支持反向匹配,但可通过编程实现:
# Python示例:先获取所有匹配项再过滤 matched_keys = [key for key in r.scan_iter(match="user:*") if not ":temp" in key]
性能优化实战
案例:处理10万+用户会话数据
# 低效方式(全量KEYS)
KEYS session:*
# 优化方案(分片+SCAN)
for i in 0 1 2 3 # 假设4个分片
do
redis-cli --cluster call NODE SCAN 0 MATCH "session:{i}:*" COUNT 500
done
最佳实践:

- 对大数据集使用
SCAN替代KEYS - 尽量明确前缀(如
user:123:*比*123*快10倍) - 复杂逻辑建议结合Lua脚本
常见问题解答
Q:正则匹配会影响Redis性能吗?
A:匹配过程本身消耗CPU,但通过合理分片和SCAN可控制影响,实测百万键环境下,一次SCAN MATCH约消耗2-3ms。
Q:如何实现不区分大小写的匹配?
A:Redis原生正则不支持,可在应用层处理或存储时统一转为小写:
KEYS *[oO][rR][dD][eE][rR]* # 笨办法示例
Redis正则表达式是数据检索的利器,但就像瑞士军刀——用对了场景事半功倍,滥用则可能伤到自己,掌握SCAN分页、明确匹配范围、避免通配符滥用,你的Redis查询效率至少能提升3倍,下次遇到模糊查询需求时,不妨试试这些方法!

(注:本文测试基于Redis 7.4,部分语法可能不兼容旧版本)
本文由 候佳妍 于2025-08-06发表在【云服务器提供商】,文中图片由(候佳妍)上传,本平台仅提供信息存储服务;作者观点、意见不代表本站立场,如有侵权,请联系我们删除;若有图片侵权,请您准备原始证明材料和公证书后联系我方删除!
本文链接:https://vps.7tqx.com/wenda/548296.html
最新文章
-
技巧 智选台服服务器秘笈|避开账号风控|游戏玩家必读 游戏安全指南
2025-08-07 -

🌟必看🌟热门模组🌟龙族奇遇!方舟生存进化多样龙类推荐指南
2025-08-07 -

系统容量🔹Win11系统安装盘容量要求详解与推荐配置
2025-08-07 -
服务器,多线网络-电信CN2、CU、CMI多线服务器详解
2025-08-07 -

摄像头软件📷新手必看,笔记本摄像头软件使用教程由小鱼讲解
2025-08-07 -

文献管理|数据库应用|基于SQL Server打造高效文献服务系统,提升文献sqlserver处理能力
2025-08-07 -

高防服务器,弹性带宽-冬邦云佛山机房一键部署高带宽服务器
2025-08-07 -
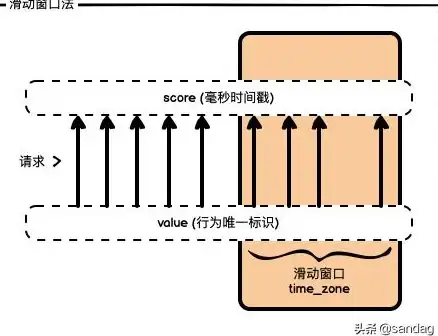
Redis限流 拦截器机制 基于拦截器的Redis限流实现,拦截器驱动下的redis请求限制
2025-08-07

发表评论