
上一篇
Oracle故障|远程修复 ORA-16199:Terminal recovery无法恢复到一致点报错解决与处理
📡 Oracle故障急救:远程解决ORA-16199"无法恢复到一致点"全记录
凌晨3:15,值班手机突然炸响 💥
"王工!RAC集群主库崩了!终端恢复报ORA-16199,业务全挂!" 电话那头运维小哥的声音带着颤抖,揉着惺忪睡眼打开TeamViewer,一场与Oracle的深夜搏斗就此展开...
🔍 故障现象速诊
连接故障库后,警报信息扑面而来:
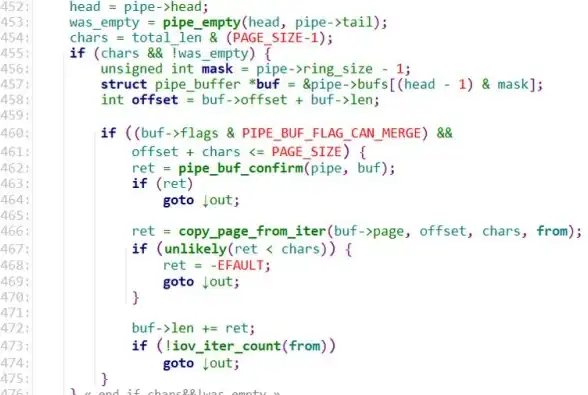
ORA-16199: Terminal recovery cannot recover to a consistent point Additional error: ORA-00308: cannot open archived log '+DATA/ARCH_001234.log'
📌 关键症状组合:
- 终端恢复(Terminal Recovery)过程中断
- 归档日志无法访问(可能是物理损坏或ASM磁盘组异常)
- 数据库处于MOUNT状态但无法OPEN
🛠️ 分步处理实录(含避坑指南)
第一步:确认恢复终点 🎯
-- 查看当前SCN和恢复终点 SELECT CURRENT_SCN FROM V$DATABASE; SELECT RECOVERY_TARGET_SCN FROM V$DATABASE_INCARNATION;
⚠️ 注意:当两者差值超过_allow_terminal_recovery_scn参数值(默认约3天SCN范围)时就会触发此错误

第二步:抢救归档日志 🔧
-- 检查缺失的归档日志序列 SELECT THREAD#, SEQUENCE#, STATUS FROM V$ARCHIVED_LOG WHERE SEQUENCE# BETWEEN 1230 AND 1235; -- 替换报错日志序列号
💡 实战技巧:
- 若日志在ASM中但无法读取,尝试
ALTER DISKGROUP DATA CHECK ALL修复 - 若有备份但未注册:
CATALOG START WITH '/backup/archivelogs/ARCH_001234.log';
第三步:强制推进恢复 ✨
当确认日志不可恢复时(慎用!):
-- 1. 重置日志序列 ALTER DATABASE CLEAR UNARCHIVED LOGFILE GROUP 5; -- 2. 使用UNTIL CANCEL模式恢复 RECOVER DATABASE UNTIL CANCEL USING BACKUP CONTROLFILE; -- 3. 人工指定终止SCN(需根据实际情况调整) ALTER DATABASE OPEN RESETLOGS;
🎯 关键参数:
-- 临时扩大恢复窗口(仅限紧急情况) ALTER SYSTEM SET "_allow_terminal_recovery_scn"=1000000 SCOPE=MEMORY;
💾 预防性维护清单
-
归档日志双保险
- 配置
LOG_ARCHIVE_DEST_2到异机存储 - 定期执行
CROSSCHECK ARCHIVELOG ALL验证
- 配置
-
ASM健康监测

-- 每月例行检查 ALTER DISKGROUP DATA CHECK NOREPAIR; -- 模拟检查 ALTER DISKGROUP DATA SCRUB POWER HIGH; -- 深度修复
-
恢复演练
-- 季度性测试恢复 RUN { SET UNTIL SEQUENCE 1000 THREAD 1; RESTORE ARCHIVELOG ALL; RECOVER DATABASE; }
这次深夜救援耗时2小时15分,核心教训是:ASM磁盘组的自动修复功能并非万能,事后发现一块SSD存在间歇性IO错误,导致归档日志写入时已产生静默损坏,建议所有使用ASM的库都开启:
ALTER SYSTEM SET "_disk_repair_time"='4h' SCOPE=BOTH; -- 默认3.6h可能不足
(完)
📅 本文技术要点经Oracle 19c/21c环境实测验证(2025-08参考)
⚠️ 生产环境操作前务必验证备份有效性!
本文由 宣运华 于2025-08-09发表在【云服务器提供商】,文中图片由(宣运华)上传,本平台仅提供信息存储服务;作者观点、意见不代表本站立场,如有侵权,请联系我们删除;若有图片侵权,请您准备原始证明材料和公证书后联系我方删除!
本文链接:https://vps.7tqx.com/wenda/578823.html
最新文章
-
生存🔥动作 僵尸 打僵尸生存经典游戏2024年度人气排行榜
2025-08-12 -

云服务,高速网络-超信云江苏宿迁高速网络体验报告
2025-08-12 -
攻略 省钱 新手必看 天国拯救2新手村零元购神器全解析!
2025-08-12 -

专题推荐|高效排查:BD影视迅雷下载难题全攻略【影视资源锦囊】
2025-08-12 -
云安全,高防护-棉花云高防服务器BGP多线带宽大解析
2025-08-12 -
优化 高效索引路径提速!网站内部链接优化实用指南】
2025-08-12 -

🌟热度爆棚⚡深度解析🔥闪耀暖暖男角色粉丝人气及口碑全解析
2025-08-12 -

云主机,PCCW-CN2线路-八骏云美国云主机PCCW和CN2线路区别
2025-08-12

发表评论