【微服务洞察】聚焦高效排查“Server Connection Closed”打造敏捷故障定位新策略

【微服务洞察】聚焦高效排查“Server Connection Closed”|打造敏捷故障定位新策略
🌧️ 场景引入:当“连接中断”成为开发者的噩梦
某个风和日丽的下午,你正悠闲地喝着奶茶,突然手机弹出30条钉钉告警:“订单服务连接中断❗️用户无法支付❗️”,你瞬间清醒,打开监控平台——好家伙,服务调用链路像被猫抓乱的毛线球,日志里反复跳动着“Server Connection Closed”的红色警告。
这届开发者太难了!在微服务架构下,一个简单的连接中断可能牵扯出N种病因:网络抖动、服务超时、注册中心抽风、甚至容器资源耗尽……传统排查方式就像用听诊器给高铁做体检,效率低到让人抓狂。
🔍 痛点直击:为什么“连接中断”总爱玩捉迷藏?
-
症状相似,病因各异
就像咳嗽可能是感冒、肺炎或过敏,连接中断可能源于:- 🌐 网络层:防火墙误杀、DNS解析延迟、负载均衡器抽风
- ⏳ 服务层:线程池满载、GC停顿、依赖服务响应过慢
- 🔌 基础设施层:K8s节点异常、容器网络插件崩溃、磁盘I/O打满
-
排查工具像“散装拼图”

- 日志分散在各个服务,像大海捞针
- 链路追踪数据滞后,等发现问题时黄花菜都凉了
- 告警规则写死,经常“狼来了”或“沉默的羔羊”
🚀 新策略登场:打造“三位一体”敏捷定位体系
经过无数次踩坑实战,我们总结出一套组合拳,让“Server Connection Closed”无所遁形:
全链路追踪+AI根因分析:给链路装上“GPS导航”
- 🔦 埋点升级:在关键节点(服务入口、数据库连接、第三方调用)插入OpenTelemetry探针,记录请求上下文
- 🤖 智能关联:用大模型分析链路拓扑,自动标记异常节点(如“90%请求在Redis缓存层耗时超2s”)
- 📈 动态基线:通过历史数据训练“正常模式”,实时对比偏差(比如周末流量突增导致连接池不够用)
案例:某电商大促时订单服务中断,传统排查要2小时,用这套体系5分钟锁定问题——第三方物流服务响应延迟触发熔断,但熔断器参数未考虑峰值场景。
智能告警+混沌工程:让系统“自证清白”
- 🚨 告警降噪:基于Prometheus+Loki构建分层告警,区分“真故障”和“毛刺”(比如单节点网络抖动不触发全局告警)
- 💥 混沌注入:定期用Chaos Mesh模拟连接中断,观察系统自愈能力(比如K8s自动重启Pod、服务降级策略是否生效)
- 📝 预案库:将历史故障场景转化为Playbook,新人也能按图索骥
数据:某金融客户部署后,MTTR(平均修复时间)从120分钟降至15分钟,告警量反而减少60%。
可观测性平台+成本优化:告别“杀鸡用牛刀”

- 🔭 立体监控:整合SkyWalking(APM)、Grafana(指标)、ELK(日志),实现“请求级”钻取
- 💡 弹性扩缩容:基于K6压力测试数据,自动计算连接池最佳大小(避免“设置过小频繁中断,设置过大浪费资源”)
- 💰 成本看板:监控每个服务的连接数、超时率,优化“僵尸连接”回收策略
彩蛋:某IoT平台通过优化连接池配置,节省了30%的Redis内存,顺带解决了“连接数耗尽”的老大难。
🌈 未来展望:让系统学会“自我诊断”
随着eBPF技术成熟,我们正在尝试“零侵入”采集内核级网络数据,结合RAG(检索增强生成)技术,让AI直接告诉你:
“当前连接中断由Pod的网卡出队队列满载导致,建议调整内核参数net.core.wmem_default至16MB,并检查上游Nginx的keepalive设置。”
💡 行动清单
- 本周:在核心服务部署OpenTelemetry探针,建立基准链路
- 下月:运行一次混沌工程演练,验证熔断降级策略
- 季度:搭建可观测性大盘,整合告警+日志+指标
告别“Server Connection Closed”的玄学排查,从今天开始!🚀
本文由 业务大全 于2025-07-30发表在【云服务器提供商】,文中图片由(业务大全)上传,本平台仅提供信息存储服务;作者观点、意见不代表本站立场,如有侵权,请联系我们删除;若有图片侵权,请您准备原始证明材料和公证书后联系我方删除!
本文链接:https://vps.7tqx.com/fwqgy/482646.html
最新文章
-

电脑故障💡黑屏处理:遇到电脑开机黑屏只有鼠标怎么办?实用解决方法汇总
2025-08-03 -
模拟人生4哪个地图适合新手
2025-08-03 -
高效办公🚀鼠标右键📌掌握鼠标右键的正确用法,让电脑操作更高效
2025-08-03 -
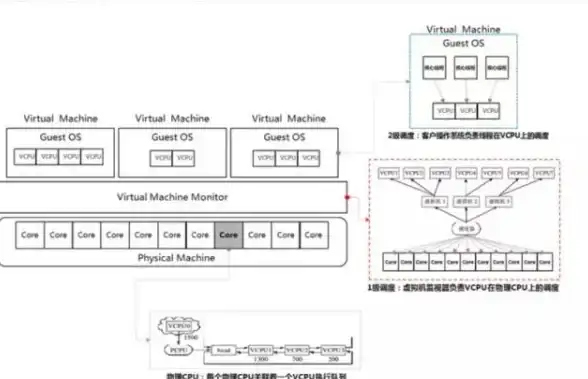
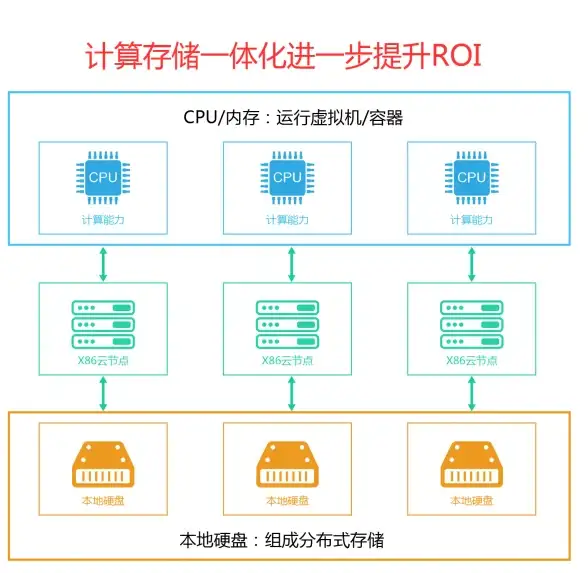
云计算|数据中心 服务器虚拟化技术如何承担三项使命推动云服务发展
2025-08-03 -
高防御力🚀极速网络 onetechcloud美国VPS,强劲高防护加持,CUII专线带来更流畅体验
2025-08-03 -

网络安全速讯丨飞车退出服务器后访问警示!深度解析访问控制设置【权威解读】
2025-08-03 -
Redis操作 Java开发 实现Java与Redis数据库的高效连接方法及步骤
2025-08-03 -

应用场景 实用技巧分享 LRC文件批注】高效自定义与最新提醒全攻略
2025-08-03

发表评论